Appearance
Java 8
通过行为参数化传递代码
行为参数化就是可以帮助你处理频繁变更的需求的一种软件开发模式。一言以蔽之,它意味着拿出一个代码块,把它准备好却不去执行它。这个代码块以后可以被你程序的其他部分调用,这意味着你可以推迟这块代码的执行。例如,你可以将代码块作为参数传递给另一个方法,稍后再去执行它。这样,这个方法的行为就基于那块代码被参数化了。
应对不断变化的需求
编写能够应对变化的需求的代码并不容易。
让我们来看一个筛选苹果的例子:
java
public class Apple {
private String color;
private Integer weight;
public Apple() {
}
public Apple(String color, Integer weight) {
this.color = color;
this.weight = weight;
}
@Override
public String toString() {
return "Apple{" + "color='" + color + '\'' + ", weight=" + weight + '}';
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
}这有一些苹果,有不同颜色的,还有不同重量的。
java
List<Apple> apples = Arrays.asList(
new Apple("红色", 158),
new Apple("红色", 120),
new Apple("黄色", 90),
new Apple("青色", 108));现在需要从列表中筛选红苹果。是不是很简单?
初出茅庐:筛选红苹果
第一种解决方案可能是下面这样的:
java
/**
* 筛选红苹果
*
* @param apples
* @return
*/
public static List<Apple> filterRedApples(List<Apple> apples) {
ArrayList<Apple> result = new ArrayList<>();
for (Apple apple : apples) {
if (apple.getColor().equals("红色")) { // 只筛选红苹果
result.add(apple);
}
}
return result;
}但是还想要筛选青苹果该怎么做呢?简单,复制这个方法,把方法名改成 filterGreenApples,然后更改 if 条件来匹配青苹果。然而,要是还想要筛选其他颜色的苹果,什么黄的啦、青的啦等,难道再复制几个方法出来更改匹配条件吗?这个时候我们就需要尝试将其抽象化,将共性的地方剥离出来。
小试牛刀:将颜色作为参数
第二种做法是给方法加一个参数,把颜色变成参数,这样就能灵活地适应需求的变化了:
java
/**
* 将颜色作为参数
*
* @param apples
* @param color
* @return
*/
public static List<Apple> filterApplesByColor(List<Apple> apples,
String color) {
ArrayList<Apple> result = new ArrayList<>();
for (Apple apple : apples) {
if (apple.getColor().equals(color)) { // 只筛选指定颜色的苹果
result.add(apple);
}
}
return result;
}现在,可以按照不同的颜色来筛选苹果了:
java
List<Apple> redApples = filterApplesByColor(apples, "红色");
List<Apple> greenApples = filterApplesByColor(apples, "青色");太简单了对吧?好,现在需求又变了:需要根据重量来区分,比如重量大于 150 的。
作为一名专业的“程序猿”,怎么可能想不到应该大概可能会根据重量来筛选呢。于是“复制/粘贴”走你,用另一个参数来表示重量:
java
/**
* 将重量作为参数
*
* @param apples
* @param weight
* @return
*/
public static List<Apple> filterApplesByWeight(List<Apple> apples,
int weight) {
ArrayList<Apple> result = new ArrayList<>();
for (Apple apple : apples) {
if (apple.getWeight() > weight) { // 只筛选大于指定重量的苹果
result.add(apple);
}
}
return result;
}解决方案不错,可是这样合适吗?遍历的代码都是一样的(对所有的苹果进行筛选),只是筛选条件不同(颜色还是重量)。这不符合 DRY(Don't Repeat Yourself,不要重复自己) 的软件工程原则。如果想要改变筛选遍历方式以提升性能,该怎么办?那就得修改所有方法的实现,而不是只改一个。从工程工作量的角度来看,这代价太大了。
有了!可以将颜色和重量结合为一个方法,就叫 filterApples。不过还需要加上一个标志来区分对颜色和重量的查询(想一想真的合适吗?)。
登堂入室:将每个可能的筛选条件作为参数
第三种是把所有的属性作为条件结合起来:
java
/**
* 将每个可能的筛选条件作为参数
*
* @param apples
* @param color
* @param weight
* @param flag
* @return
*/
public static List<Apple> filterApples(List<Apple> apples, String color,
int weight, boolean flag) {
ArrayList<Apple> result = new ArrayList<>();
for (Apple apple : apples) {
if ((flag && apple.getColor().equals(color))
|| (!flag && apple.getWeight() > weight)) {
result.add(apple);
}
}
return result;
}可以这样用:
java
List<Apple> redApples = filterApples(apples, "红色", 0, true);
List<Apple> heavyApples = filterApples(apples, "", 150, false);最差代码不过如此。首先,true 和 false 表示什么可能都要猜上一会儿。其次,如果苹果还有别的属性,比如大小、形状、产地等,还要按照这些属性做筛选又怎么办?此外,可能还会有更复杂的组合条件查询,比如:大于 120 的红苹果,小于 100 的青苹果等。难道要挨个“复制/粘贴”然后再修改吗?
行为参数化
让我们先退一步来好好想一想:不变的是什么?变的又是什么?
不变的是需要对苹果进行筛选,变的是筛选条件不一样。好,那能不能根据苹果的筛选条件(比如它是红色的吗?重量超过 150 吗?)来返回一个 boolean 值呢?可以把它称为谓词(Predicate,即一个返回 boolean值的函数)。
先定义一个 Predicate 接口对选择标准建模:
java
/**
* 根据条件筛选苹果的接口
*/
public interface ApplePredicate {
/**
* 检查苹果是否满足指定的条件
*
* @param apple
* @return
*/
boolean test(Apple apple);
}不同的选择标准就是不同的筛选条件:
java
public class RedColorApplePredicate implements ApplePredicate {
/**
* 检查苹果颜色是否是红色
*
* @param apple
* @return
*/
@Override
public boolean test(Apple apple) {
return "红色".equals(apple.getColor());
}
}
public class HeavyWeightApplePredicate implements ApplePredicate {
/**
* 检查苹果重量是否大于 150
*
* @param apple
* @return
*/
@Override
public boolean test(Apple apple) {
return apple.getWeight() > 150;
}
}我们可以把这些标准看作 filterApples 方法的不同行为。你刚做的这些和“策略设计模式”相关,它让你定义一族算法,把它们封装起来(称为“策略”),然后在运行时选择一个算法。在这里,算法族就是 ApplePredicate,不同的策略就是RedColorApplePredicate 和 HeavyWeightApplePredicate。
要筛选苹果,就将 ApplePredicate 传入 filterApples 方法对每一个苹果做条件筛选。这就是行为参数化:让方法接受多种行为(策略)作为参数,并在内部使用,来完成不同的行为。
游刃有余:根据抽象条件筛选
这是第四种解决方案,filterApples 方法看起来是这样的:
java
/**
* 将筛选苹果的条件作为参数
*
* @param apples
* @param applePredicate
* @return
*/
public static List<Apple> filterApples(List<Apple> apples, ApplePredicate applePredicate) {
ArrayList<Apple> result = new ArrayList<>();
for (Apple apple : apples) {
if (applePredicate.test(apple)) { // 只筛选满足指定条件的苹果
result.add(apple);
}
}
return result;
}现在可以创建不同的 ApplePredicate,并将它们传递给 filterApples 方法。比如,要找出所有重量大于 150 的红苹果:
java
public class RedColorAndHeavyWeightApplePredicate
implements ApplePredicate {
/**
* 检查苹果颜色是否是红色并且重量大于 150
*
* @param apple
* @return
*/
@Override
public boolean test(Apple apple) {
return "红色".equals(apple.getColor())
&& apple.getWeight() > 150;
}
}
List<Apple> redColorAndHeavyWeightApples = filterApples(apples,
new RedColorAndHeavyWeightApplePredicate());太酷了!filterApples 方法的行为取决于通过 ApplePredicate 传递的代码。换句话说,我们把 filterApples 方法的行为参数化了!
可是,如果还有新的行为,就得声明好几个实现 ApplePredicate 接口的类,然而这些类大部分都只会被实例化一次,岂不浪费。
费这么大劲儿真没必要,能不能做得更好呢?
炉火纯青:使用匿名类
Java 有一个机制称为匿名类,它可以同时声明和实例化一个类。
下面的代码展示了如何通过创建一个用匿名类实现 ApplePredicate 的对象,筛选红苹果的例子:
java
List<Apple> redApples = filterApples(apples, new ApplePredicate() {
@Override
public boolean test(Apple apple) {
return "红色".equals(apple.getColor());
}
});但匿名类还是不够好。每当定义一个新的行为时,还是得先创建一个对象,才能实现具体的方法(例如 ApplePredicate 接口中的 test 方法)。
java
List<Apple> redApples = filterApples(apples, new ApplePredicate() {
@Override
public boolean test(Apple apple) {
return "红色".equals(apple.getColor());
}
});
List<Apple> redColorAndHeavyWeightApples = filterApples(apples,
new ApplePredicate() {
@Override
public boolean test(Apple apple) {
return "红色".equals(apple.getColor())
&& apple.getWeight() > 150;
}
});简而言之,模板代码太多。当然,那是在 Java 8 之前。
登峰造极:使用 Lambda 表达式
Java 8 通过引入 Lambda 表达式,一种更简洁的传递代码的方式,解决了这个问题。
上面的代码在 Java 8 里可以用 Lambda 表达式重写为下面的样子:
java
List<Apple> redApples = filterApples(apples,
(Apple apple) -> "红色".equals(apple.getColor()));
List<Apple> redColorAndHeavyWeightApples = filterApples(apples,
(Apple apple) -> "红色".equals(apple.getColor())
&& apple.getWeight() > 150);不得不承认现在的代码看上去比先前干净很多。而且它看起来更像问题陈述本身了。
到此为止了么?假如还要筛选香蕉、桔子甚至是 Integer 或是 String,难道还要再写一个对应的 filter 方法?
返璞归真:将类型抽象化
Java 的另外一个机制称为泛型,它可以使 List 和 Predicate 类型参数化,而不必拘泥于其中一种类型。
java
/**
* 根据条件筛选指定元素的接口
*/
public interface Predicate<T> {
/**
* 检查指定元素是否满足指定的条件
*
* @param t
* @return
*/
boolean test(T t);
}
/**
* 将筛选指定元素的条件作为参数
*
* @param list
* @param p
* @return
*/
public static <T> List<T> filter(List<T> list, Predicate<T> p) {
ArrayList<T> result = new ArrayList<>();
for (T t : list) {
if (p.test(t)) { // 只筛选满足指定条件的元素
result.add(t);
}
}
return result;
}使用 Lambda 表达式的例子:
java
List<Apple> redApples = filter(apples,
(Apple apple) -> "红色".equals(apple.getColor()));
List<Integer> evenNumbers = filter(Arrays.asList(1, 2, 3, 4, 5, 6),
(Integer integer) -> integer % 2 == 0);酷不酷?我们现在在灵活性和简洁性之间找到了最佳平衡点,这在 Java 8 之前是不可能做到的!
行为参数化的例子
Java API 中的很多方法都可以用不同的行为来参数化。这些方法往往与匿名类一起使用。
下面是几个例子,分别使用匿名类和 Lambda 表达式来编写。
使用
Comparator进行排序在 Java 8 中,
List自带了一个sort方法(也可以使用原来的Collections.sort)。sort的行为可以用java.util.Comparator对象来参数化。java// 使用匿名类,根据重量对苹果进行排序 apples.sort(new Comparator<Apple>() { @Override public int compare(Apple a1, Apple a2) { return a1.getWeight().compareTo(a2.getWeight()); } }); // 使用 Lambda 表达式,根据重量对苹果进行排序 apples.sort((Apple a1, Apple a2) -> a1.getWeight() .compareTo(a2.getWeight()));使用
Runnable执行代码块在 Java 里,使用
Thread中的start方法开启一个新线程,然后可以将Runnable接口中run方法里的代码放在新线程执行。java// 使用匿名类,在新线程中输出“Hello, World!” new Thread(new Runnable() { @Override public void run() { System.out.println("Hello, World!"); } }).start(); // 使用 Lambda 表达式,在新线程中输出“Hello, World!” new Thread(() -> System.out.println("Hello, World!")).start();
现在知道了为什么要使用 Lambda 表达式(Why),它可以很简洁地表示一个行为或传递代码。那么,什么是 Lambda 表达式 (What)?如何使用 Lambda 表达式(How)?
Lambda 表达式
什么是 Lambda 表达式
可以把 Lambda 表达式理解为一种简洁的可传递匿名函数:它没有名称,但它有参数列表、函数主体、返回类型,可能还有一个可以抛出的异常列表。
是不是很好奇 Lambda 这个词是从哪儿来的?其实它来自于数学中的 λ 演算,其中的 λ 读作 Lambda(希腊字母表中排序第十一位的字母,大写为 Λ,英语名称为 Lambda)。
Lambda 表达式的特点
理论上来说,你在 Java 8 之前做不了的事情,Lambda 也做不了。但是,现在再也用不着使用匿名类写一堆笨重的代码,来体验行为参数化的好处了!最终结果就是你的代码变得更清晰、更灵活。
下面是 Lambda 表达式的几个特点:
匿名
说它是匿名的,是因为它不像普通的方法那样有一个明确的名称,这样就不会因为写得少而想得多了(起名字脑阔疼)!
函数
说它是一种函数,是因为 Lambda 函数不像方法那样属于某个特定的类。但和方法一样,Lambda 有参数列表、函数主体、返回类型,还可能有可以抛出的异常列表。
传递
Lambda 表达式可以作为参数传递给方法或存储在变量中。
简洁
无需像匿名类那样写很多模板代码。
Lambda 表达式的组成
Lambda 表达式由参数、箭头和主体组成:

(Lambda 表达式由参数、箭头和主体组成,图片来源:Java 8 实战)
参数列表
这里采用了
Comparator中compare方法的参数,两个Apple。箭头
箭头
->把参数列表与 Lambda 主体分隔开。Lambda 主体
比较两个
Apple的重量。表达式就是Lambda的返回值。
Lambda 的基本语法是:
表达式分格的 Lambda (parameters) -> expression 或块风格 的 Lambda (parameters) -> { statements; }。
为了进一步说明,下面给出了 Java 8 中五个有效的 Lambda 表达式的例子。
java
(String s) -> s.length() // 第一个 Lambda 表达式具有一个 String 类型的参数并返回一个 int。没有 return 语句,因为已经隐含了 return
(Apple a) -> a.getWeight() > 150 // 第二个 Lambda 表达式有一个 Apple 类型的参数并返回一个 boolean(苹果的重量是否超过 150)
(int x, int y) -> { // 第三个 Lambda 表达式具有两个 int 类型的参数而没有返回值(void 返回)。注意 Lambda 表达式可以包含多行语句,这里是两行
System.out.println("Result:");
System.out.println(x+y);
}
() -> 42 // 第四个 Lambda 表达式没有参数, 返回一个 int
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()) // 第五个 Lambda 表达式具有两个 Apple 类型的参数,返回一个 int:比较两个 Apple 的重量Lambda 表达式的使用案例
| 使用案例 | Lambda 示例 |
|---|---|
| 布尔表达式 | (List<String> list) -> list.isEmpty() |
| 创建对象 | () -> new Apple("红色", 120) |
| 消费一个对象 | (Apple a) -> { System.out.println(a.getWeight()); } |
| 从一个对象中选择/抽取 | (String s) -> s.length() |
| 组合两个值 | (int a, int b) -> a * b |
| 比较两个对象 | (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()) |
如何使用 Lambda 表达式
那到底在哪里可以使用 Lambda 呢?可以在函数式接口上使用 Lambda 表达式。
在上面的代码中,可以把 Lambda 表达式作为第二个参数传给 filter 方法,因为这里是一个 Predicate<T>,而 Predicate<T> 就是一个函数式接口。
函数式接口
函数式接口就是只定义一个抽象方法的接口。例如: Comparator 接口,里面只有一个抽象的 compare 方法;还有 Runnable 接口,里面只有一个抽象的 run 方法。
java
@FunctionalInterface
public interface Comparator<T> { // java.util.Comparator
int compare(T o1, T o2);
}
@FunctionalInterface
public interface Runnable{ // java.lang.Runnable
void run();
}@FunctionalInterface 注解又是怎么回事?
在 Java 8 中,函数式接口会有一个 @FunctionalInterface 注解。
如果你用 @FunctionalInterface 定义了一个接口,里面的抽象方法却不止一个的话,编译器会提示 Multiple non-overriding abstract methods found in interface xxx,表明存在多个抽象方法。
请注意,@FunctionalInterface 不是必需的,但它是一个规范。就跟 @Override 注解表示方法已经被重写了一样。
一言以蔽之,带有 @FunctionalInterface 注解的接口就是函数式接口。
Lambda 表达式允许直接以内联的形式为函数式接口的抽象方法提供实现,并把整个表达式作为函数式接口的实例(具体说来,是函数式接口一个具体实现的实例)。你用匿名内部类也可以完成同样的事情,只不过比较笨拙:需要提供一个实现,然后再直接内联将它实例化。
java
Runnable r1 = () -> System.out.println("Hello, World!"); // 使用 Lambda 表达式
Runnable r2 = new Runnable(){ // 使用匿名类
public void run(){
System.out.println("Hello, World!");
}
};
new Thread(() -> System.out.println("Hello, World!")).start(); // 使用直接传递的 Lambda 表达式函数式接口中抽象方法的签名(方法参数)基本上就是 Lambda 表达式的签名(函数参数)。我们将这种抽象方法叫作函数描述符。
例如,Runnable 接口可以看作一个什么也不接受什么也不返回(void)的函数的签名,因为它只有一个叫作 run 的抽象方法,这个方法什么也不接受,什么也不返回(void)。
java
Runnable r = () -> System.out.println("Hello, World!");使用函数式接口
函数式接口很有用,因为抽象方法的签名可以描述 Lambda 表达式的签名。函数式接口的抽象方法的签名称为函数描述符。
在 Java 8 之前,Java API 中已经有了几个函数式接口,比如 Comparator、Runnable。在 Java 8 中,java.util.function 包引入了几个新的函数式接口。
下面介绍几个常用的新函数式接口:
Predicate
java.util.function.Predicate<T>接口定义了一个名叫test的抽象方法,它接受泛型T对象,并返回一个boolean。这恰恰和我们先前创建的一样(好巧哦),现在就可以直接使用了。在需要表示一个涉及类型
T的布尔表达式时,就可以使用这个接口。java@FunctionalInterface public interface Predicate<T>{ boolean test(T t); } // 测试一个字符串是不是不为空(谓词型) Predicate<String> nonEmptyStringPredicate = (String s) -> !s.isEmpty(); boolean test = nonEmptyStringPredicate.test("Hello, World!"); System.out.println(test); // trueConsumer
java.util.function.Consumer<T>定义了一个名叫accept的抽象方法,它接受泛型T的对象,没有返回(void)。如果需要访问类型
T的对象,并对其执行某些操作,就可以使用这个接口。java@FunctionalInterface public interface Consumer<T>{ void accept(T t); } // 接受一个字符串并打印第一个字符(消费型) Consumer<String> printFirstCharConsumer = (String s) -> System.out .println(s.charAt(0)); printFirstCharConsumer.accept("Hello, World!"); // HFunction
java.util.function.Function<T, R>接口定义了一个叫作apply的方法,它接受一个泛型T的对象,并返回一个泛型R的对象。如果需要将输入对象
T的信息映射到输出对象R,就可以使用这个接口。java@FunctionalInterface public interface Function<T, R>{ R apply(T t); } // 得到一个字符串的长度(功能型) Function<String, Integer> stringLengthFunction = (String s) -> s .length(); Integer integer = stringLengthFunction.apply("Hello, World!"); System.out.println(integer); // 13
Lambda 及函数式接口的例子
| 使用案例 | Lambda 的例子 | 对应的函数式接口 |
|---|---|---|
| 布尔表达式 | (List<String> list) -> list.isEmpty() | Predicate<List<String>> |
| 创建对象 | () -> new Apple(10) | Supplier<Apple> |
| 消费一个对象 | (Apple a) -> System.out.println(a.getWeight()) | Consumer<Apple> |
| 从一个对象中选择/提取 | (String s) -> s.length() | Function<String, Integer> 或 ToIntFunction<String> |
| 合并两个值 | (int a, int b) -> a * b | IntBinaryOperator |
| 比较两个对象 | (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()) | Comparator<Apple> 或 BiFunction<Apple, Apple, Integer> 或 ToIntBiFunction<Apple, Apple> |
方法引用
方法引用让你可以重复使用现有的方法定义,并像 Lambda 一样传递它们。
什么是方法引用?
方法引用可以被看作仅仅调用特定方法的 Lambda 的一种快捷写法。
它的基本思想是,如果一个 Lambda 代表的只是“直接调用这个方法”,那最好还是用名称来调用它,而不是去描述如何调用它。事实上,方法引用就是让你根据已有的方法实现来创建 Lambda 表达式。但是,显式地指明方法的名称,你的代码的可读性会更好。
它是如何工作的呢?当你需要使用方法引用时,目标引用放在分隔符 :: 前,方法的名称放在后面。例如,String::length 就是引用了 String 类中定义的方法 length。请记住,不需要括号,因为你没有实际调用这个方法。方法引用就是 Lambda 表达式 (String s) -> s.length() 的快捷写法。
下面是 Lambda 及其等效方法引用的例子:
| Lambda | 等效的方法引用 |
|---|---|
(Apple a) -> a.getWeight() | Apple::getWeight |
(str, i) -> str.substring(i) | String::substring |
(String s) -> System.out.println(s) | System.out::println |
可以把方法引用看作针对仅仅涉及单一方法的 Lambda 的语法糖,因为表达同样的事情时要写的代码更少了。
如何构建方法引用
方法引用主要有三类:
指向静态方法的方法引用(例如
Integer的parseInt方法,写作Integer::parseInt)。指向任意类型实例方法的方法引用(例如
String的length方法,写作String::length)。指向现有对象或表达式实例方法的方法引用(假设有一个局部变量
s用于存放String类型的对象,它支持实例方法length,那么就可以写s::length)。
第二种和第三种方法引用的区别是:方法引用所在的对象本身是否为 Lambda 的一个参数。如果引用一个对象的方法,而这个对象本身是 Lambda 的一个参数,就属于第二种;如果在 Lambda 中调用的是一个已经存在的外部对象中的方法,就属于第三种。
下面是一份将 Lambda 表达式重构为等价方法引用的简易速查表。
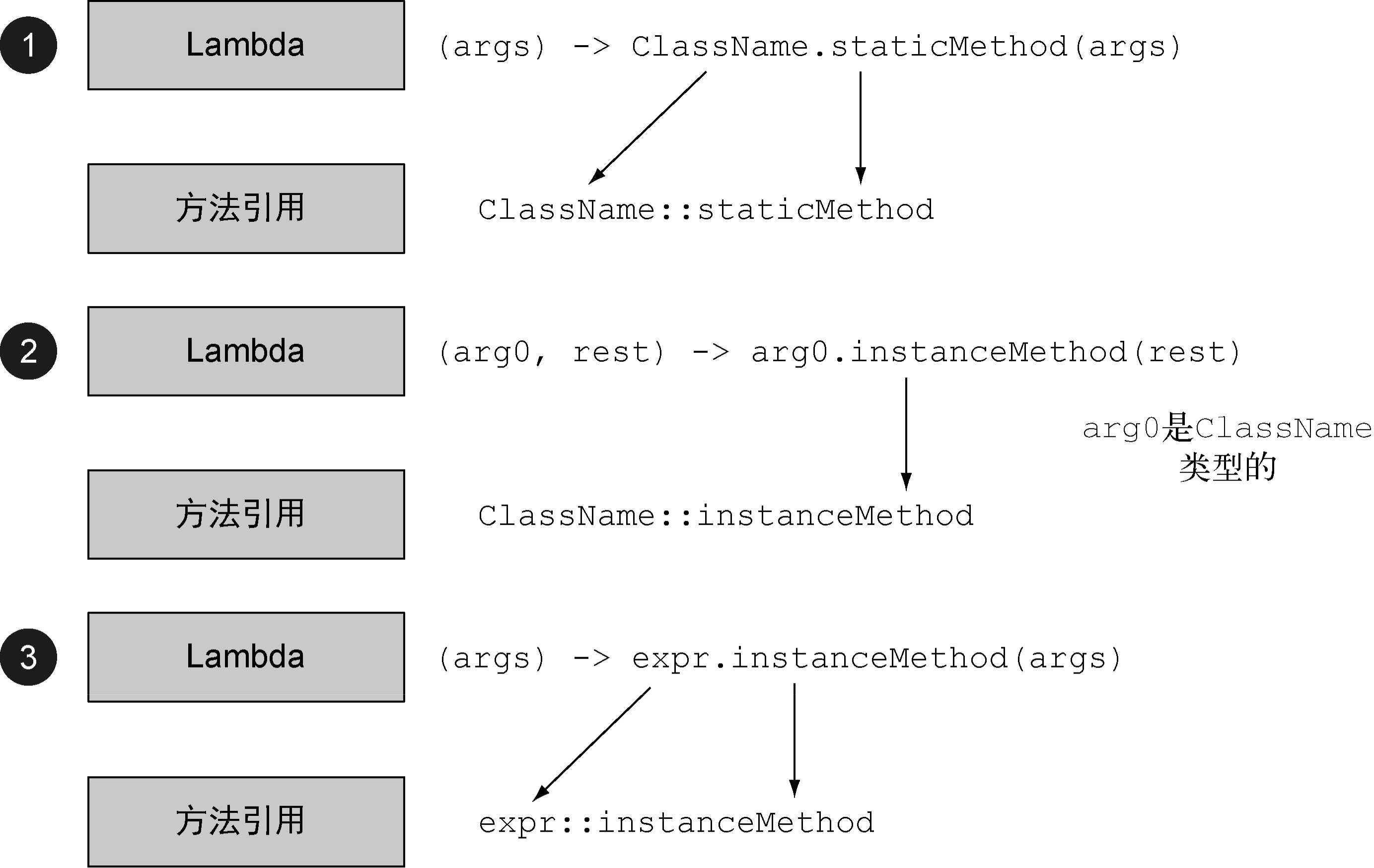
(为三种不同类型的 Lambda 表达式构建方法引用的办法,图片来源:Java 实战)
请注意,还有针对构造函数、数组构造函数和父类调用(super-call)的一些特殊形式的方法引用。
构造函数引用
对于一个现有构造函数,可以利用它的名称和关键字 new 来创建它的一个引用:ClassName::new。它的功能与指向静态方法的引用类似。
下面是构造函数引用的例子:
java
public class Apple {
private String color;
private Integer weight;
public Apple() {
}
public Apple(Integer weight) {
this.weight = weight;
}
public Apple(String color, Integer weight) {
this.color = color;
this.weight = weight;
}
@Override
public String toString() {
return "Apple{" +
"color='" + color + '\'' +
", weight=" + weight +
'}';
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
}没有参数的构造函数引用
没有参数的构造函数适合
Supplier的签名。java// 没有参数的构造函数引用 // 指向 Apple() 的构造函数引用 Supplier<Apple> appleSupplier = Apple::new; // 调用 Supplier 的 get 方法将产生一个新的 Apple 对象 Apple apple = appleSupplier.get(); // 等价于下面: // 用默认构造函数创建 Apple 的 Lambda 表达式 Supplier<Apple> appleSupplier1 = () -> new Apple(); // 调用 Supplier 的 get 方法将产生一个新的 Apple 对象 Apple apple1 = appleSupplier1.get();一个参数的构造函数引用
一个参数的构造函数适合
Function的签名。java// 一个参数的构造函数引用 // 指向 Apple(Integer weight) 的构造函数引用 Function<Integer, Apple> appleFunction = Apple::new; // 调用 Function 的 apply 方法,并给出要求的重量,将产生一个 Apple 对象 Apple apple = appleFunction.apply(120); // 等价于下面: // 用要求的重量创建 Apple 的 Lambda 表达式 Function<Integer, Apple> appleFunction1 = (Integer i) -> new Apple(i); // 调用 Function 的 apply 方法,并给出要求的重量,将产生一个 Apple 对象 Apple apple1 = appleFunction1.apply(120);两个参数的构造函数引用
两个参数的构造函数适合
BiFunction的签名。java// 两个参数的构造函数引用 // 指向 Apple(String color, Integer weight) 的构造函数引用 BiFunction<String, Integer, Apple> appleBiFunction = Apple::new; // 调用 BiFunction 的 apply 方法,并给出要求的颜色和重量,将产生一个新的 Apple 对象 Apple apple = appleBiFunction.apply("红色", 120); // 等价于下面: // 用要求的颜色和重量创建 Apple 的 Lambda 表达式 BiFunction<String, Integer, Apple> appleBiFunction1 = (String s, Integer i) -> new Apple(s, i); // 调用 BiFunction 的 apply 方法,并给出要求的颜色和重量,将产生一个新的 Apple 对象 Apple apple1 = appleBiFunction1.apply("红色", 120);
从匿名类到 Lambda 表达式的转换
某些情况下,将匿名类转换为 Lambda 表达式可能是一个比较复杂的过程。下面是转换过程中需要注意的地方:
匿名类和 Lambda 表达式中的
this和super的含义是不同的。在匿名类中,this代表的是类自身,但是在 Lambda 中,它代表的是包含类。java/** * 在匿名类中,`this` 代表的是类自身,但是在 Lambda 中,它代表的是包含类 */ public void diff1() { new Thread(new Runnable() { @Override public void run() { // 匿名类中的 this:(匿名类没有名字) System.out.println( "匿名类中的 this:" + this.getClass().getSimpleName()); } }).start(); new Thread(() -> { // Lambda 中的 this:LambdaExample System.out.println( "Lambda 中的 this:" + this.getClass().getSimpleName()); }).start(); }匿名类可以屏蔽包含类的变量,而 Lambda 表达式不能(它们会导致编译错误)。
java/** * 匿名类可以屏蔽包含类的变量,而 Lambda 表达式不能(它们会导致编译错误) */ public void diff2() { int a = 10; Runnable r1 = new Runnable() { public void run() { // 一切正常 int a = 2; System.out.println(a); } }; Runnable r2 = () -> { // 编译错误!(已在方法 diff2()中定义了变量 a)
// int a = 2; System.out.println(a); }; } ```
在涉及重载的上下文里,将匿名类转换为 Lambda 表达式可能导致最终的代码更加晦涩。
假设用与
Runnable同样的签名声明了一个函数接口Task:javainterface Task { void execute(); } public void doSomething(Runnable r) { r.run(); } public void doSomething(Task a) { a.execute(); }java/** * 传递一个匿名类实现的 Task,不会碰到任何问题,而转换为 Lambda 表达式会导致模棱两可 */ public void diff3() { // 一切正常 doSomething(new Task() { public void execute() { System.out.println("Danger danger!!"); } }); // 编译错误!(对doSomething的引用不明确)
// doSomething(() -> { // System.out.println("Danger danger!!"); // }); } ```
使用显式的类型转换来解决这种模棱两可的情况:
```java
// 使用显式的类型转换
doSomething((Task) () -> {
System.out.println("Danger danger!!");
});
```
Stream 流
Java 8 新增了 Stream API,它允许你以声明性方式处理数据集合(通过查询语句来表达(就像 SQL 一样),而不是临时编写一个实现)。
我们简单看看使用流的好处吧。
Dish 类:
java
public class Dish {
private String name;
private boolean vegetarian;
private int calories;
private Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
@Override
public String toString() {
return "Dish{" +
"name='" + name + '\'' +
", calories=" + calories +
", vegetarian=" + vegetarian +
", type=" + type +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public boolean isVegetarian() {
return vegetarian;
}
public void setVegetarian(boolean vegetarian) {
this.vegetarian = vegetarian;
}
public int getCalories() {
return calories;
}
public void setCalories(int calories) {
this.calories = calories;
}
public Type getType() {
return type;
}
public void setType(Type type) {
this.type = type;
}
enum Type { MEAT, FISH, OTHER }
}菜肴列表:
java
List<Dish> menu = Arrays.asList(
new Dish("猪肉", false, 800, Dish.Type.MEAT),
new Dish("牛肉", false, 700, Dish.Type.MEAT),
new Dish("鸡肉", false, 400, Dish.Type.MEAT),
new Dish("炸薯条", true, 530, Dish.Type.OTHER),
new Dish("米饭", true, 350, Dish.Type.OTHER),
new Dish("苹果", true, 120, Dish.Type.OTHER),
new Dish("披萨", true, 550, Dish.Type.OTHER),
new Dish("对虾", false, 300, Dish.Type.FISH),
new Dish("三文鱼", false, 450, Dish.Type.FISH));下面两段代码都是用来返回低热量的菜肴名称的,并按照卡路里排序,一个是用 Java 7 写的,另一个是用 Java 8 的流写的。
之前(Java 7):
javaList<Dish> lowCaloricmenu = new ArrayList<>(); // 临时创建一个集合 for (Dish d: menu) { if (d.getCalories() < 400) { // 迭代筛选元素 lowCaloricmenu.add(d); } } Collections.sort(lowCaloricmenu, new Comparator<Dish>() { // 用匿名类排序 public int compare(Dish d1, Dish d2){ return Integer.compare(d1.getCalories(), d2.getCalories()); } }); List<String> lowCaloricmenuName = new ArrayList<>(); for (Dish d: lowCaloricmenu) { lowCaloricmenuName.add(d.getName()); // 处理排序后的列表 }
上面代码中,需要先准备一个 List,然后筛选元素放到这个集合中,接着排序这个集合,最后再次遍历这个集合,将菜肴的名称放到一个新的 List 中。
在 Java 8 中,一切都变得那么简单。
之后(Java 8):
javaList<String> lowCaloricmenu = menu.stream() // 转换为流 .filter(d -> d.getCalories() < 400) // 过滤元素 .sorted(Comparator.comparing(Dish::getCalories)) // 排序 .map(Dish::getName) // 提取名称 .collect(Collectors.toList()); // 保存到 List
代码是以声明性方式写的:只需要说明想要完成什么(筛选热量低的菜肴)而不是说明如何实现一个操作(利用循环和条件等控制语句)。

(图片来源:Java 8 实战)
什么是流
简短的定义就是“从支持数据处理操作的源生成的元素序列”。
元素序列
就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如
ArrayList与LinkedList)。但流的目的在于表达计算,比如前面见到的filter、sorted和map。集合讲的是数据,流讲的是计算。源
流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
数据处理操作
流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如
filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
流的两个重要特点
流水线
很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。流水线的操作可以看作对数据源进行数据库式查询。
内部迭代
与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
java
List<String> threeHighCaloricDishNames =
menu.stream() // 获得流
.filter(d -> d.getCalories() > 300) // 建立操作流水线:首先选出高热量的菜肴
.map(Dish::getName) // 获取菜名
.limit(3) // 只选择头三个
.collect(Collectors.toList()); // 将结果保存在另一个 List 中
System.out.println(threeHighCaloricDishNames); // [猪肉, 牛肉, 鸡肉]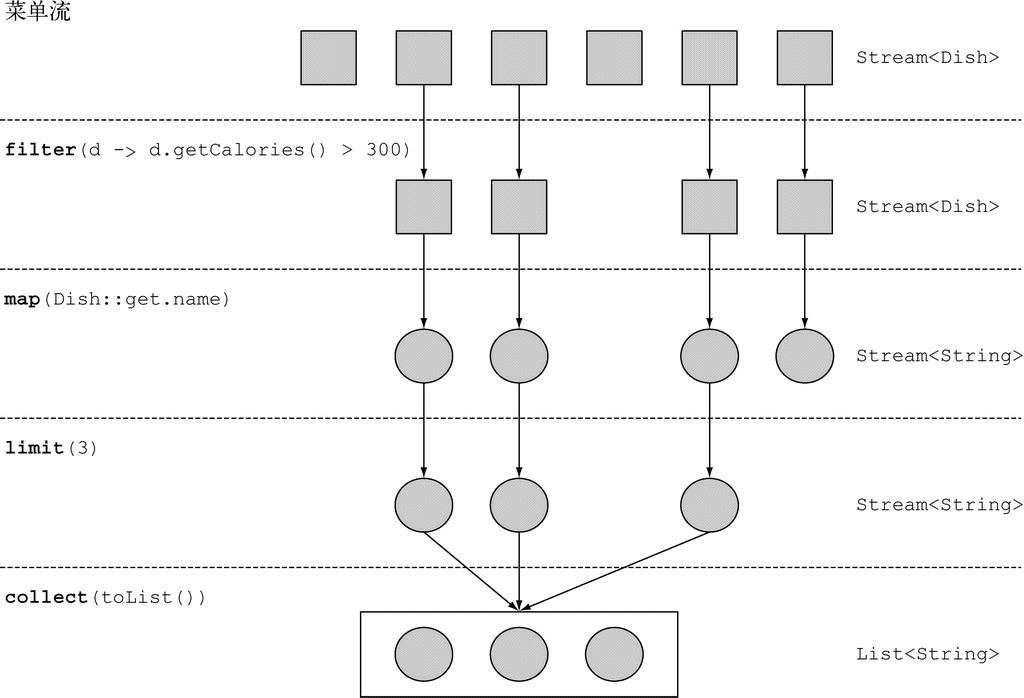
(图片来源:Java 8 实战)
在上面的代码中: 先是对 menu 调用 stream 方法,由菜肴列表得到一个流。数据源是菜肴列表,它给流提供一个元素序列。
接下来,对流应用一系列数据处理操作:filter、map、limit 和 collect。除了 collect 之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流水线,于是就可以看作对源的一个查询。
最后,collect 操作开始处理流水线,并返回结果(它和别的操作不一样,因为它返回的不是流,在这里是一个 List)。在调用 collect 之前,没有任何结果产生,实际上根本就没有从 menu 里选择元素。可以这么理解:链中的方法调用都在排队等待,直到调用 collect。
流与集合
Java 现有的集合概念和新的流概念都提供了接口,来配合代表元素型有序值的数据接口。所谓有序,就是说我们一般是按顺序取用值,而不是随机取用的。那这两者有什么区别呢?
两个例子
看视频
比如说
DVD里的电影,这就是一个集合(也许是字节,也许是帧,这个无所谓),因为它包含了整个数据结构。在互联网上通过视频流看电影,这是一个流(字节流或帧流)。只要提前下载观看位置的那几帧就可以了,这样不用等到流中大部分值计算出来,就可以显示流的开始部分(想想观看直播世界杯)。
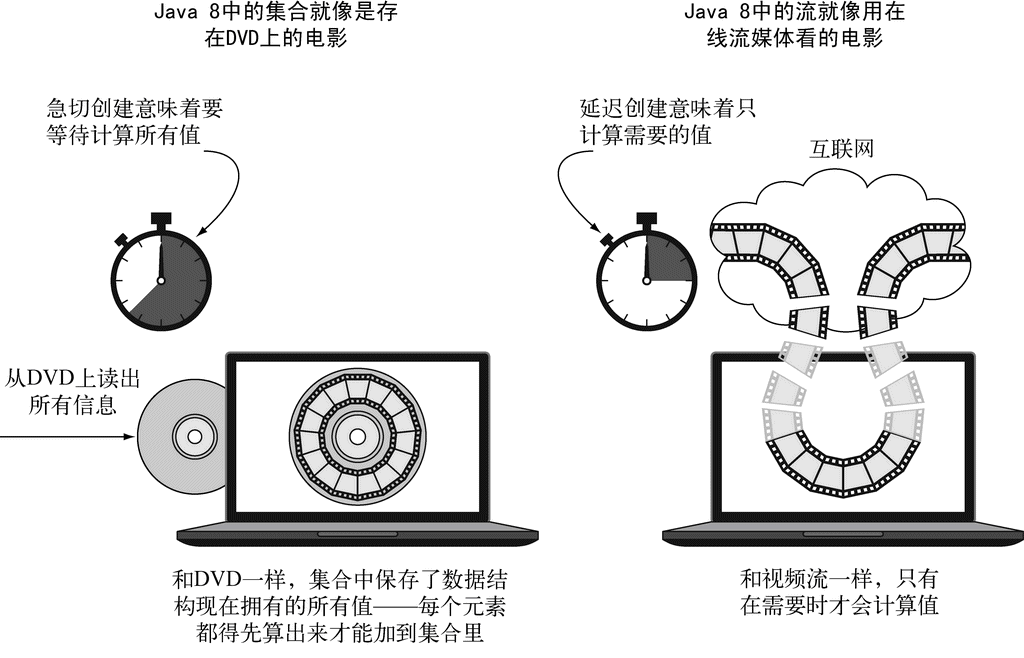
(图片来源:Java 8 实战)
互联网搜索
另一个例子是用浏览器进行互联网搜索。假设搜索的短语在 Google 或是百度里面有很多匹配项,我们并没有等到所有结果集合都下载完,而是先得到一个流,里面有最好的 10个或 20个匹配项,还有一个按钮来查看下面 10个或 20个。当点击“下面 10个”的时候,搜索引擎才会按需计算这些结果,然后再显示出来。
粗略地说,集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)
相比之下,流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。 这是一种生产者-消费者的关系。
从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值(用管理学的话说这就是需求驱动,甚至是实时制造)。
与此相反,集合则是急切创建的(供应商驱动:先把仓库装满,再开始卖)。
流只能消费一次
和迭代器类似,流只能遍历一次。遍历完之后,我们就说这个流已经被消费掉了。你可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样(这里假设它是集合之类的可重复的源,如果是 I/O 通道就没戏了)。
例如,以下代码会抛出一个异常,说流已被消费掉了:
java
List<String> list = Arrays.asList("Hello", "Java 8", "helloworld.study");
Stream<String> stream = list.stream();
stream.forEach(System.out::println); // 打印结果
stream.forEach(System.out::println); // 再次打印结果:
java
Hello
Java 8
helloworld.study
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed外部迭代与内部迭代
使用 Collection 接口需要用户去做迭代(比如用for-each),这称为外部迭代。 相反,Stream API 使用内部迭代——它帮你把迭代做了,还把得到的流值存在了某个地方,你只要给出一个函数说要干什么就可以了。
集合:用
for-each循环和迭代器进行外部迭代java// for-each List<String> names = new ArrayList<>(); for(Dish d: menu){ // 显式顺序迭代菜单列表 names.add(d.getName()); // 提取名称并将其添加到 List } // 迭代器 List<String> names = new ArrayList<>(); Iterator<String> iterator = menu.iterator(); while(iterator.hasNext()) { // 显式迭代 Dish d = iterator.next(); names.add(d.getName()); }流:内部迭代
javaList<String> names = menu.stream() .map(Dish::getName) // 用 `getName` 方法参数化 `map`,提取菜名 .collect(Collectors.toList()); // 开始执行操作流水线;没有迭代!
流操作
java.util.stream.Stream 中的 Stream 接口定义了许多操作。它们可以分为两大类:中间操作和终端操作。
java
List<String> names = menu.stream() // 获得流
.filter(d -> d.getCalories() > 300) // 中间操作
.map(Dish::getName) // 中间操作
.limit(3) // 中间操作
.collect(Collectors.toList()); // 将 Stream 转换为 List上面的例子中:
filter、map和limit可以连成一条流水线;collect触发流水线执行并关闭它。
可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。
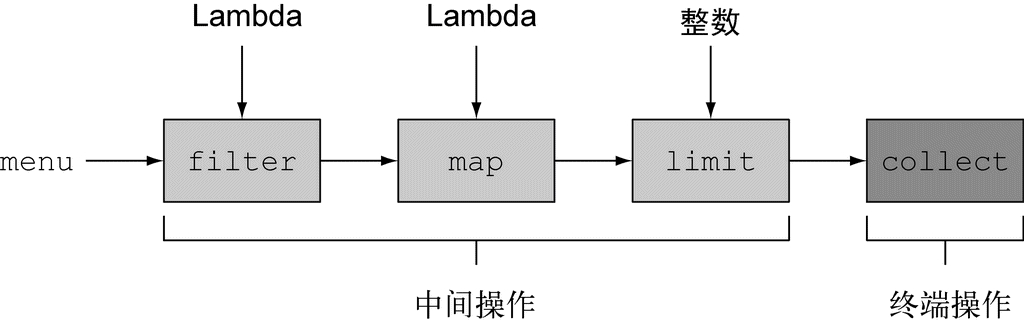
(图片来源:Java 8 实战)
这种区分有什么意义呢?
中间操作
诸如 filter 或 sorted 等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。
为了搞清楚流水线中到底发生了什么,我们把代码改一改,让每个 Lambda 都打印出当前处理的菜肴:
java
List<String> names =
menu.stream()
.filter(d -> {
System.out.println("filtering..." + d.getName());
return d.getCalories() > 300;
}) // 打印当前筛选的菜肴
.map(d -> {
System.out.println("mapping..." + d.getName());
return d.getName();
}) // 提取菜名时打印出来
.limit(3)
.collect(Collectors.toList());
System.out.println(names);结果:
java
filtering...猪肉
mapping...猪肉
filtering...牛肉
mapping...牛肉
filtering...鸡肉
mapping...鸡肉
[猪肉, 牛肉, 鸡肉]尽管 filter 和 map 是两个独立的操作,但它们合并到同一次遍历中了(循环合并)。
终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如 List、Integer,甚至 void。
例如,在下面的流水线中,forEach 是一个返回 void 的终端操作,它会对源中的每道菜应用一个 Lambda。把 System.out.println 传递给 forEach,并要求它打印出由 menu 生成的流中的每一个 Dish:
java
menu.stream().forEach(System.out::println);结果:
java
Dish{name='猪肉', calories=800, vegetarian=false, type=MEAT}
Dish{name='牛肉', calories=700, vegetarian=false, type=MEAT}
Dish{name='鸡肉', calories=400, vegetarian=false, type=MEAT}
Dish{name='炸薯条', calories=530, vegetarian=true, type=OTHER}
Dish{name='米饭', calories=350, vegetarian=true, type=OTHER}
Dish{name='苹果', calories=120, vegetarian=true, type=OTHER}
Dish{name='披萨', calories=550, vegetarian=true, type=OTHER}
Dish{name='对虾', calories=300, vegetarian=false, type=FISH}
Dish{name='三文鱼', calories=450, vegetarian=false, type=FISH}使用流的步骤
流的使用一般包括三件事:
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
部分中间流操作:
| 操作 | 类型 | 返回类型 | 操作参数 | 函数描述符 |
|---|---|---|---|---|
filter | 中间 | Stream<T> | Predicate<T> | T -> boolean |
map | 中间 | Stream<R> | Function<T, R> | T -> R |
limit | 中间 | Stream<T> | ||
sorted | 中间 | Stream<T> | Comparator<T> | (T, T) -> int |
distinct | 中间 | Stream<T> |
部分终端流操作:
| 操作 | 类型 | 目的 |
|---|---|---|
forEach | 终端 | 消费流中的每个元素并对其应用 Lambda。这一操作返回 void |
count | 终端 | 返回流中元素的个数。这一操作返回 long |
collect | 终端 | 把流归约成一个集合,比如 List、Map 甚至是 Integer |
Stream 流的使用
Stream API支持许多操作。这些操作能快速完成复杂的数据查询,如筛选、截断、映射、查找、匹配和归约。
筛选和截断
我们来看看如何选择流中的元素:用谓词筛选,筛选出各不相同的元素,忽略流中的头几个元素,或将流截断至指定长度。
filter
filter 方法接受一个谓词(一个返回 boolean 的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
以下代码会筛选出所有素菜,创建一张素食菜单:
java
// filter
List<Dish> vegetarianMenu = menu.stream()
.filter(Dish::isVegetarian) // 方法引用检查菜肴是否是素食
.collect(Collectors.toList());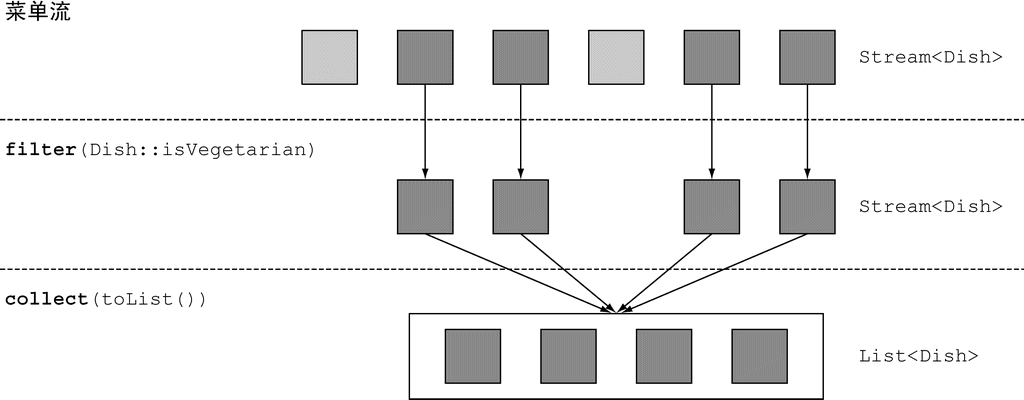
(图片来源:Java 8 实战)
distinct
distinct 方法会返回一个元素各异(根据流所生成元素的 hashCode 和 equals 方法实现)的流。
以下代码会筛选出列表中所有的偶数,并确保没有重复:
java
// distinct
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);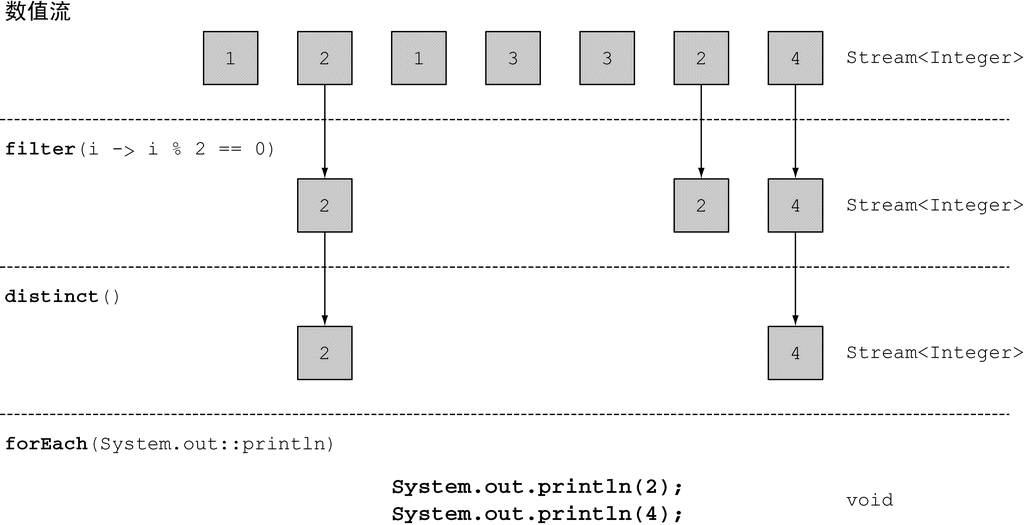
(图片来源:Java 8 实战)
limit
limit 方法会返回一个不超过给定长度的流。所需的长度作为参数传递给 limit。如果流是有序的,则最多会返回前 n 个元素。
以下代码会选出热量超过 300 卡路里的头三道菜:
java
// limit
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.limit(3)
.collect(Collectors.toList());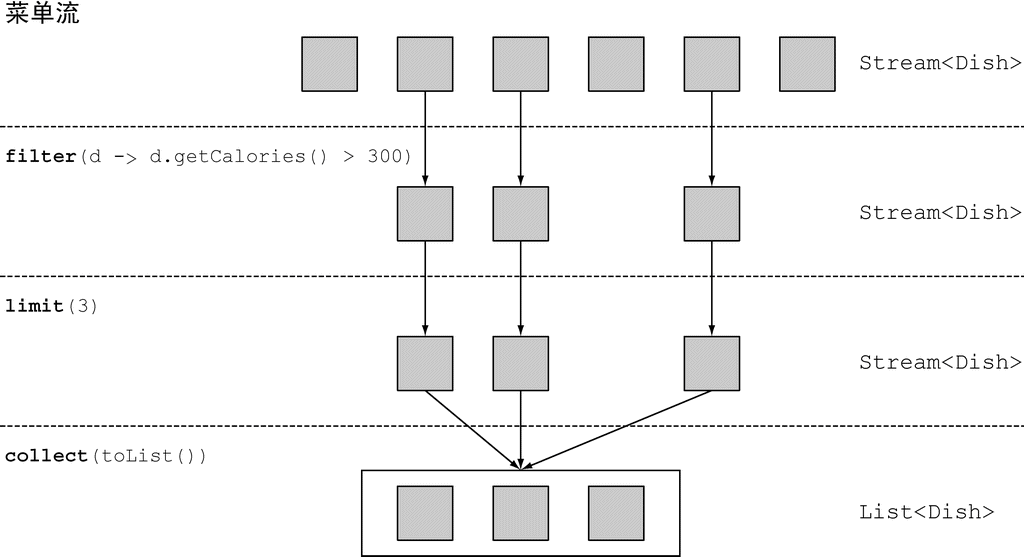
(图片来源:Java 8 实战)
skip
skip 方法会返回一个扔掉了前 n 个元素的流。如果流中元素不足 n 个,则返回一个空流。请注意,limit(n) 和 skip(n) 是互补的!
以下代码会跳过超过 300 卡路里的头两道菜,并返回剩下的:
java
// skip
List<Dish> dishes = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(2)
.collect(Collectors.toList());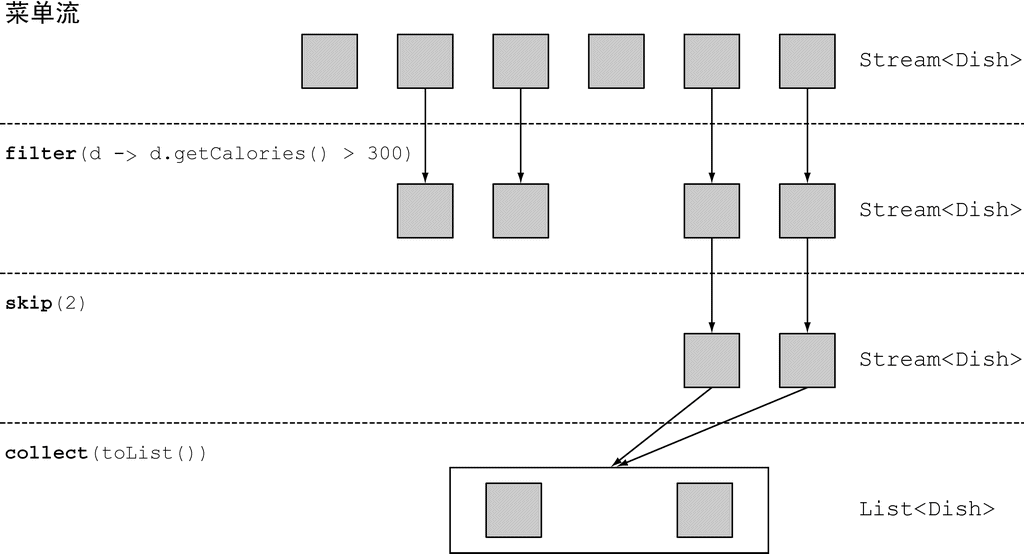
(图片来源:Java 8 实战)
映射
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在 SQL 里,你可以从表中选择一列。Stream API 也通过 map 和 flatMap 方法提供了类似的工具。
map
map 方法会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”)。
以下代码把方法引用 Dish::getName 传给了 map 方法,来提取流中菜肴的名称:
java
// map
List<String> dishNames = menu.stream()
.map(Dish::getName)
.collect(Collectors.toList());flatMap
flatMap 方法会把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
下面的例子说明了 map 和 flatMap 的不同之处。
对于一张单词表,如何返回一张列表,列出里面各不相同的字符呢?例如,给定单词列表["Hello","World"],你想要返回列表["H","e","l", "o","W","r","d"]。
java
List<String> words = Arrays.asList("Hello", "World");
// 目标是返回列表:["H","e","l", "o","W","r","d"]第一次尝试:可以把每个单词映射成一张字符表,然后调用
distinct来过滤重复的字符:javaList<String[]> strings = words.stream() .map(word -> word.split("")) // 将每个单词转换为由其字母构成的数组 .distinct() .collect(Collectors.toList()); // [[Ljava.lang.String;@6e8cf4c6, [Ljava.lang.String;@12edcd21]
这个方法的问题在于,传递给 map 方法的 Lambda 为每个单词返回了一个 String[]。因此,map 返回的流实际上是 Stream<String[]> 类型的。我们真正想要的是用 Stream<String> 来表示一个字符流。
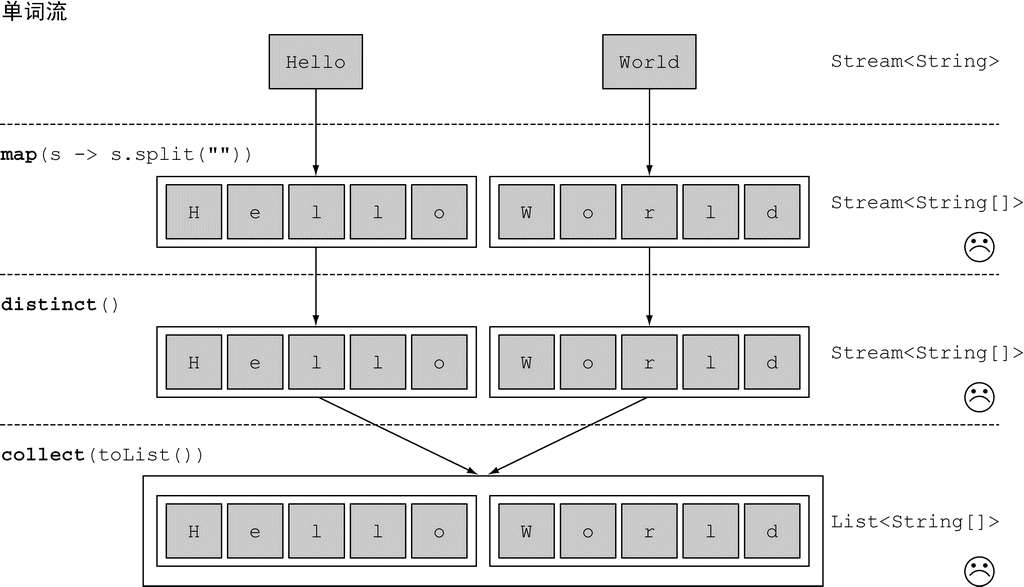
(图片来源:Java 8 实战)
我们需要的是字符流,而不是数组流。在 Java 8 中,新增了一个叫作 Arrays.stream() 的方法可以接受一个数组并产生一个流,例如:
java
Stream<String> wordsStream = Arrays.stream(words.toArray(new String[0]));第二次尝试:使用
map和Arrays.stream():javaList<Stream<String>> strings = words.stream() .map(word -> word.split("")) // 将每个单词转换为由其字母构成的数组 .map(Arrays::stream) // 让每个数组变成一个单独的流 .distinct() .collect(Collectors.toList()); // [java.util.stream.ReferencePipeline$Head@52cc8049, java.util.stream.ReferencePipeline$Head@5b6f7412]
当前的解决方案仍然搞不定!这是因为,现在得到的是一个流的列表( Stream<Stream<String>>),而我们需要的是 <Stream<String>。
第三次尝试:使用
flatMapjava// flatMap List<String> strings = words.stream() .map(word -> word.split("")) // 将每个单词转换为由其字母构成的数组 .flatMap(Arrays::stream) // 将每个数组生成的流扁平化为单个流 .distinct() .collect(Collectors.toList()); // [H, e, l, o, W, r, d]
使用 flatMap 方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用 map(Arrays::stream) 时生成的单个流都被合并起来,即扁平化为一个流。
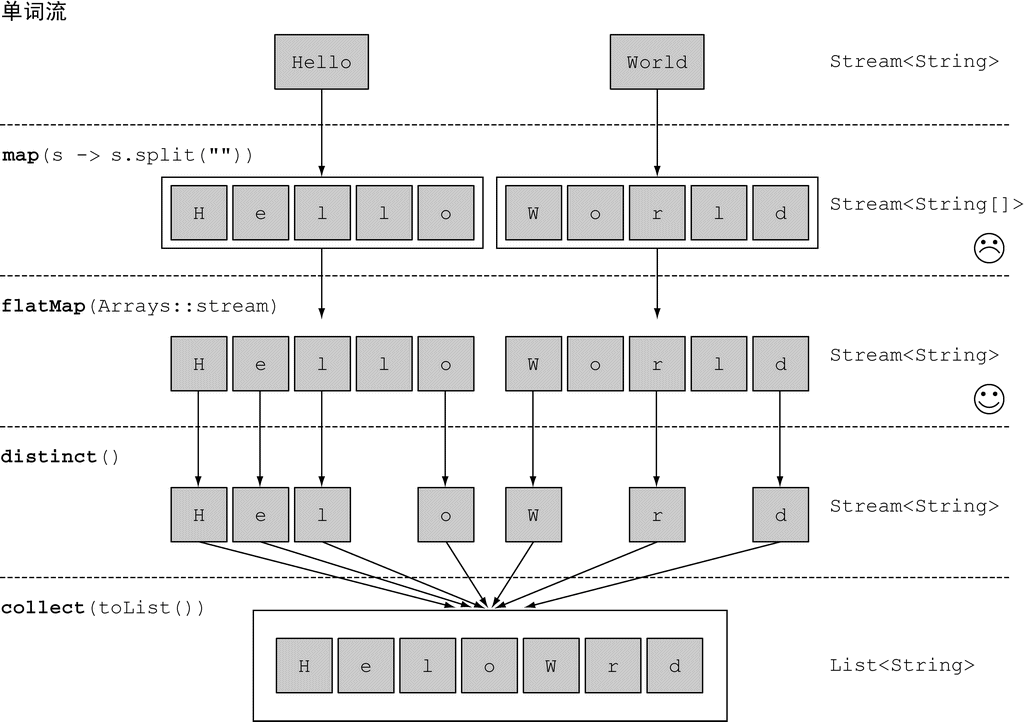
(图片来源:Java 8 实战)
查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API 通过 anyMatch、allMatch、noneMatch、findAny和 findFirst 方法提供了这样的工具。
anyMatch
anyMatch 方法可以判断流中是否有一个元素能匹配给定的谓词。
以下代码会查看菜单里面是否有素食可选择:
java
// anyMatch
boolean anyMatch = menu.stream()
.anyMatch(Dish::isVegetarian);
if (anyMatch) { // true
System.out.println("菜单里面有素食");
}allMatch 和 noneMatch
allMatch方法可以判断流中的元素是否都能匹配给定的谓词。以下代码会查看所有菜的热量是否都低于 1000 卡路里:
java// allMatch boolean allMatch = menu.stream() .allMatch(dish -> dish.getCalories() < 1000); if (allMatch) { // true System.out.println("所有菜的热量都低于 1000 卡路里"); }noneMatch方法与allMatch方法相反,它可以确保流中没有任何元素与给定的谓词匹配。以下代码会查看所有菜的热量是否都不高于 1000 卡路里:
java// noneMatch boolean noneMatch = menu.stream() .noneMatch(dish -> dish.getCalories() >= 1000); if (noneMatch) { // true System.out.println("所有菜的热量都不高于 1000 卡路里"); }
findAny 和 findFirst
findAny方法将返回当前流中的任意元素。比如,想找到一道素食菜肴,可以结合使用
filter和findAny方法来实现这个查询:java// findAny Optional<Dish> optionalDish = menu.stream() .filter(Dish::isVegetarian) .findAny();
为什么返回的是 Optional?
Optional<T> 类(java.util.Optional)是一个容器类,代表一个值存在或不存在。在上面的代码中,findAny 可能什么元素都没找到。
例如,在前面的代码中需要显式地检查 Optional 对象中是否存在一道菜可以访问其名称:
java
optionalDish.ifPresent(dish -> System.out.println(dish.getName())); // 炸薯条ifPresent(Consumer<T> action)会在值存在的时候执行给定的代码块。
详情请查看:用 Optional 取代 null
有些流有一个出现顺序(encounter order)来指定流中项目出现的逻辑顺序(比如由
List或排序好的数据列生成的流)。对于这种流,你可能想要找到第一个元素。为此有一个findFirst方法,它的工作方式类似于findany。例如,给定一个数字列表,下面的代码能找出第一个平方能被 3 整除的数:
java// findFirst List<Integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5); Optional<Integer> firstSquareDivisibleByThree = someNumbers.stream() .map(x -> x * x) .filter(x -> x % 3 == 0) .findFirst(); firstSquareDivisibleByThree.ifPresent(System.out::println); // 9
何时使用 findFirst 和 findAny?
为什么会同时有 findFirst 和 findAny 呢?答案是并行。找到第一个元素在并行上限制更多。如果不关心返回的元素是哪个,请使用 findAny,因为它在使用并行流时限制较少。
有关并行,请查看:Stream 并行流
归约
可以使用 reduce 操作把一个流中的元素组合起来表达更复杂的查询。比如“计算菜单中的总卡路里”或“菜单中卡路里最高的菜是哪一个”。此类查询需要将流中所有元素反复结合起来,得到一个值,比如一个 Integer。这样的查询可以被归类为归约操作(将流归约成一个值)。
用函数式编程语言的术语来说,这称为折叠(fold),因为可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,而这就是折叠操作的结果。
下面是一个数字列表:
java
List<Integer> numbers = Arrays.asList(4, 5, 3, 9);元素求和
先来看看如何使用 for-each 循环来对数字列表中的元素求和:
java
int sum = 0;
for (int x : numbers) {
sum += x;
}numbers 中的每个元素都用加法运算符反复迭代来得到结果。通过反复使用加法,我们把一个数字列表归约成了一个数字。
这段代码中有两个参数:
- 总和变量的初始值,在这里是 0;
- 将列表中所有元素结合在一起的操作,在这里是
+运算。
要是还能把所有的数字相乘,而不必去复制粘贴这段代码,岂不是很好?这正是 reduce 操作的用武之地,它对这种重复应用的模式做了抽象。
可以像下面这样对流中所有的元素求和:
java
Integer sum = numbers.stream()
.reduce(0, (a, b) -> a + b);reduce 接受两个参数:
- 一个初始值,这里是0;
- 一个
BinaryOperator<T>来将两个元素结合起来产生一个新值,这里用的是 Lambda:(a, b) -> a + b。
现在也很容易把所有的元素相乘,只需要将另一个 Lambda:(a, b) -> a * b 传递给 reduce 操作就可以了:
java
Integer product = numbers.stream()
.reduce(1, (a, b) -> a * b);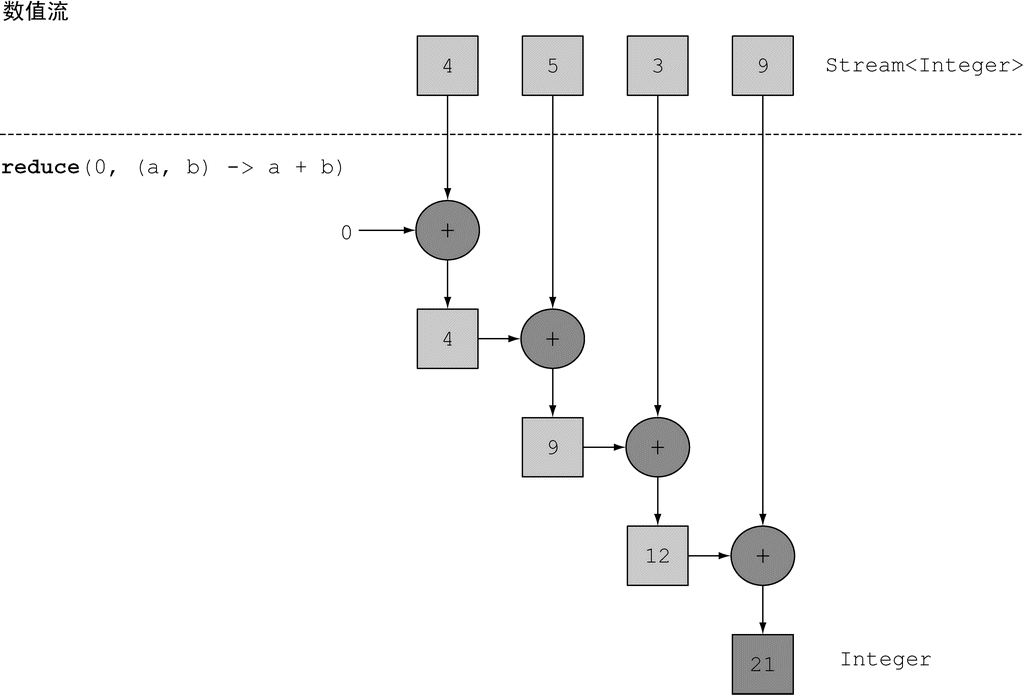
(图片来源:Java 8 实战)
在 Java 8 中,Integer 类现在有了一个静态的 sum 方法来对两个数求和:
java
Integer sum = numbers.stream()
.reduce(0, Integer::sum);提示
reduce 还有一个重载的变体,它不接受初始值,但是会返回一个 Optional 对象:
java
Optional<Integer> sum = numbers.stream()
.reduce((a, b) -> a + b);为什么返回一个 Optional<Integer> 呢?考虑流中没有任何元素的情况。reduce 操作无法返回其和,因为它没有初始值。
最大值和最小值
可以像下面这样使用 reduce 来计算流中的最大值和最小值:
最大值
javaOptional<Integer> max = numbers.stream() .reduce((a, b) -> a > b ? a : b); Optional<Integer> max = numbers.stream() .reduce(Integer::max);最小值
javaOptional<Integer> min = numbers.stream() .reduce((a, b) -> a < b ? a : b); Optional<Integer> min = numbers.stream() .reduce(Integer::min);
提示
怎样用 map 和 reduce 方法数一数流中有多少个菜呢?
答案:可以把流中每个元素都映射成数字 1,然后用 reduce 求和。这相当于按顺序数流中的元素个数。
java
Integer count = menu.stream()
.map(d -> 1)
.reduce(0, (a, b) -> a + b);map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名,因为它很容易并行化。
统计元素个数的另一种方式是使用 Java 8 中 Stream 实例的 count 方法:
java
long count = menu.stream()
.count();流操作:无状态和有状态
诸如 map 或 filter 等操作会从输入流中获取每一个元素,并在输出流中得到 0 或 1 个结果。这些操作一般都是无状态的:它们没有内部状态(假设提供的 Lambda 或方法引用没有内部可变状态)。
相反,诸如 sort 或 distinct 等操作一开始都和 filter 和 map 差不多——都是接受一个流,再生成一个流(中间操作),但有一个关键的区别。从流中排序和删除重复项时都需要知道先前的历史。这些操作叫作有状态操作。
使用 Collectors 收集数据
Collectors 实用类提供了很多静态工厂方法,可以方便地创建常见收集器的实例,只要拿来用就可以了。最直接和最常用的收集器是 toList 静态方法,它会把流中所有的元素收集到一个 List 中:
java
// toList
List<Dish> dishes = menu.stream()
.collect(Collectors.toList());Collectors 类中的工厂方法主要提供了三大功能:
将流元素归约和汇总为一个值
元素分组
元素分区
归约和汇总
先来举一个简单的例子,利用 counting 工厂方法返回的收集器,数一数菜单里有多少种菜:
java
// counting
Long howManyDishes = menu.stream()
.collect(Collectors.counting());还可以写得更为直接:
java
long howManyDishes = menu.stream().count();查找流中的最大值和最小值
假设想要找出菜单中热量最高或最低的菜。可以使用两个收集器,Collectors.maxBy 和 Collectors.minBy,来计算流中的最大或最小值。这两个收集器接收一个 Comparator 参数来比较流中的元素。
java
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories);
// maxBy
Optional<Dish> mostCalorieDish = menu.stream()
.collect(Collectors.maxBy(dishCaloriesComparator));汇总
Collectors 类专门为汇总提供了一个工厂方法:Collectors.summingInt。它可接受一个把对象映射为求和所需 int 的函数,并返回一个收集器;该收集器在传递给普通的 collect 方法后即执行我们需要的汇总操作。
举个例子来说,你可以这样求出菜单列表的总热量:
java
// summingInt
Integer totalCalories = menu.stream()
.collect(Collectors.summingInt(Dish::getCalories));Collectors.summingLong 和 Collectors.summingDouble 方法的作用完全一样,可以用于求和字段为 long 或 double 的情况。
汇总不仅仅是求和;还有 Collectors.averagingInt,连同对应的 averagingLong 和 averagingDouble 可以计算数值的平均数:
java
// averagingInt
Double avgCalories = menu.stream()
.collect(Collectors.averagingInt(Dish::getCalories));提示
不过很多时候,你可能想要得到两个或更多这样的结果,而且你希望只需一次操作就可以完成。在这种情况下,你可以使用 summarizingInt 工厂方法返回的收集器。
例如,通过一次 summarizing 操作可以就数出菜单中元素的个数,并得到菜肴热量总和、平均值、最大值和最小值:
java
// summarizingInt
IntSummaryStatistics menuStatistics = menu.stream()
.collect(Collectors.summarizingInt(Dish::getCalories));这个收集器会把所有这些信息收集到一个叫作 IntSummaryStatistics 的类里,它提供了方便的取值(getter)方法来访问结果。打印 menuStatistics 会得到以下输出:
java
IntSummaryStatistics{count=9, sum=4200, min=120, average=466.666667, max=800}同样,相应的 summarizingLong 和 summarizingDouble 工厂方法有相关的 LongSummaryStatistics 和 DoubleSummaryStatistics 类型,适用于收集的属性是原始类型 long 或 double 的情况。
连接字符串
joining 工厂方法返回的收集器会把对流中每一个对象应用 toString 方法得到的所有字符串连接成一个字符串。
例如,把菜单中所有菜肴的名称连接起来:
java
// joining
String shortMenu = menu.stream()
.map(Dish::getName)
.collect(Collectors.joining());请注意,joining 在内部使用了 StringBuilder 来把生成的字符串逐个追加起来。
结果产生以下字符串:
java
猪肉牛肉鸡肉炸薯条米饭苹果披萨对虾三文鱼但该字符串的可读性并不好。幸好,joining 工厂方法有一个重载版本可以接受元素之间的分界符,这样你就可以得到一个逗号分隔的菜肴名称列表:
java
String shortMenu = menu.stream()
.map(Dish::getName)
.collect(Collectors.joining(", "));它会生成:
java
猪肉, 牛肉, 鸡肉, 炸薯条, 米饭, 苹果, 披萨, 对虾, 三文鱼广义的归约汇总
事实上,上面讨论的所有收集器,都可以用 reducing 工厂方法重新定义。只不过 Java API 帮我们封装好了常用的功能。
例如,可以用 reducing 方法创建的收集器来计算菜单的总热量,如下所示:
java
// reducing
Integer totalCalories = menu.stream()
.collect(
Collectors.reducing(0, Dish::getCalories, (i, j) -> i + j));它需要三个参数:
第一个参数是归约操作的起始值,也是流中没有元素时的返回值。这里对于数值的和而言 0 是一个合适的值。
第二个参数是一个
Function。这里将菜肴转换成一个表示其所含热量的int。第三个参数是一个
BinaryOperator,将两个项目累积成一个同类型的值。这里是对两个int求和。
同样,可以使用下面这样单参数形式的 reducing 来找到热量最高的菜,如下所示:
java
Optional<Dish> mostCalorieDish = menu.stream()
.collect(
Collectors.reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));分组
一个常见的数据库操作是根据一个或多个属性对集合中的项目进行分组。如果在 Java 8 之前,这个操作可能会很麻烦、啰嗦而且容易出错。但是,如果用 Java 8 所推崇的函数式风格来重写的话,就很容易转化为一个非常容易看懂的语句。
例如,使用 Collectors.groupingBy 工厂方法把菜单中的菜按照类型进行分类:
java
// groupingBy
Map<Dish.Type, List<Dish>> dishesByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType));其结果是一个 Map:
java
{FISH=[Dish{name='对虾'}, Dish{name='三文鱼'}],
MEAT=[Dish{name='猪肉'}, Dish{name='牛肉'}, Dish{name='鸡肉'}],
OTHER=[Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]}这里,给 groupingBy 方法传递了一个 Function(以方法引用的形式),它提取了流中每一道 Dish 的 Dish.Type。这里的 Function 叫作分类函数,因为它用来把流中的元素分成不同的组。
多级分组
要实现多级分组,可以使用一个由双参数版本的 Collectors.groupingBy 工厂方法创建的收集器,它除了普通的分类函数之外,还可以接受 Collector 类型作为第二个参数。
例如,菜单中的菜先按照类型进行分类,再按照是否是素食进行分组:
java
// groupingBy
Map<Dish.Type, Map<Boolean, List<Dish>>> dishesByTypeAndVegetarian = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.groupingBy(Dish::getVegetarian)));二级分组的结果就是像下面这样的两级 Map:
java
{FISH={false=[Dish{name='对虾'}, Dish{name='三文鱼'}]},
MEAT={false=[Dish{name='猪肉'}, Dish{name='牛肉'}, Dish{name='鸡肉'}]},
OTHER={true=[Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]}}按子组收集数据
传递给第一个 groupingBy 的第二个收集器可以是任何类型,而不一定是另一个 groupingBy。
例如,要数一数菜单中每类菜有多少个,可以传递 counting 收集器作为 groupingBy 收集器的第二个参数:
java
Map<Dish.Type, Long> typesCount = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.counting()));其结果是下面的 Map:
java
{FISH=2, MEAT=3, OTHER=4}再举一个例子,按照菜的类型分类,并找出每种类型中热量最高的菜肴:
java
Map<Dish.Type, Optional<Dish>> mostCaloricByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))));结果:
java
{FISH=Optional[Dish{name='三文鱼'}], MEAT=Optional[Dish{name='猪肉'}], OTHER=Optional[Dish{name='披萨'}]}提示
一般来说,分组操作的 Map 结果中的每个值上包装的 Optional 没什么用,我们可能想要把它们去掉。或者更一般地来说,把收集器返回的结果转换为另一种类型,可以使用 Collectors.collectingAndThen 工厂方法返回的收集器:
java
Map<Dish.Type, Dish> mostCaloricByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get)));这个工厂方法接受两个参数——要转换的收集器以及转换函数,并返回另一个收集器。这个收集器相当于旧收集器的一个包装,collect 操作的最后一步就是将返回值用转换函数做一个映射。在这里,被包起来的收集器就是用 maxBy 建立的那个,而转换函数 Optional::get 则把返回的 Optional 中的值提取出来。这个操作放在这里是安全的,因为 reducing 收集器永远都不会返回 Optional.empty()。
结果:
java
{FISH=Dish{name='三文鱼'}, MEAT=Dish{name='猪肉'}, OTHER=Dish{name='披萨'}}与 groupingBy 联合使用的其他收集器的例子
一般来说,通过 groupingBy 工厂方法的第二个参数传递的收集器将会对分到同一组中的所有流元素执行进一步归约操作。例如,重用求出所有菜肴热量总和的收集器,不过这次是对每一组 Dish 求和:
java
Map<Dish.Type, Integer> totalCaloriesByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.summingInt(Dish::getCalories)));
System.out.println(totalCaloriesByType); // {FISH=750, MEAT=1900, OTHER=1550}常常和 groupingBy 联合使用的另一个收集器是 mapping 方法生成的。这个方法接受两个参数:一个函数对流中的元素做变换,另一个则将变换的结果对象收集起来。其目的是在累加之前对每个输入元素应用一个映射函数,这样就可以让接受特定类型元素的收集器适应不同类型的对象。比方说你想要知道,对于每种类型的 Dish,菜单中都有哪些 “卡路里级别(DIET,NORMAL,FAT)”。我们可以把 groupingBy 和 mapping 收集器结合起来:
java
Map<Dish.Type, Set<String>> caloricLevelsByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.mapping(dish -> { if (dish.getCalories() <= 400) return "DIET";
else if (dish.getCalories() <= 700) return "NORMAL";
else return "FAT"; }, Collectors.toSet())));
System.out.println(caloricLevelsByType); // {FISH=[DIET, NORMAL], MEAT=[DIET, FAT, NORMAL], OTHER=[DIET, NORMAL]}上面的示例对于返回的 Set 是什么类型并没有任何保证。但通过使用 toCollection 就可以有更多的控制。例如,可以给它传递一个构造函数引用来要求是 HashSet:
java
Map<Dish.Type, Set<String>> caloricLevelsByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType,
Collectors.mapping(dish -> { if (dish.getCalories() <= 400) return "DIET";
else if (dish.getCalories() <= 700) return "NORMAL";
else return "FAT"; }, Collectors.toCollection(HashSet::new))));分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,可以把它称为分区函数。分区函数返回一个布尔值,这意味着得到的分组 Map 的键类型是 Boolean,也就是说它最多可以分为两组——true 是一组,false 是一组。
例如,如果想要把菜单按照素食和非素食分开:
java
// partitioningBy
Map<Boolean, List<Dish>> partitionedMenu = menu.stream()
.collect(Collectors.partitioningBy(Dish::getVegetarian));这会返回下面的 Map:
java
{false=[Dish{name='猪肉'}, Dish{name='牛肉'}, Dish{name='鸡肉'}, Dish{name='对虾'}, Dish{name='三文鱼'}],
true=[Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]}那么通过 Map 中键为 true 的值,就可以找出所有的素食菜肴了:
java
List<Dish> vegetarianDishes = partitionedMenu.get(true);
System.out.println(vegetarianDishes); // [Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]请注意,用同样的分区谓词,对菜单 List 创建的流作筛选,然后把结果收集到另外一个 List 中也可以获得相同的结果:
java
List<Dish> vegetarianDishes = menu.stream()
.filter(Dish::getVegetarian)
.collect(Collectors.toList());
System.out.println(vegetarianDishes); // [Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]分区的优势
分区的好处在于保留了分区函数返回 true 或 false 的两套流元素列表。
而且就像在分组中看到的,partitioningBy 工厂方法有一个重载版本,可以像下面这样传递第二个收集器:
java
Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType = menu.stream()
.collect(Collectors.partitioningBy(Dish::getVegetarian,
Collectors.groupingBy(Dish::getType)));
System.out.println(vegetarianDishesByType); // {false={FISH=[Dish{name='对虾'}, Dish{name='三文鱼'}], MEAT=[Dish{name='猪肉'}, Dish{name='牛肉'}, Dish{name='鸡肉'}]}, true={OTHER=[Dish{name='炸薯条'}, Dish{name='米饭'}, Dish{name='苹果'}, Dish{name='披萨'}]}}再举一个例子,我们可以重用前面的代码来找到素食和非素食中热量最高的菜:
java
Map<Boolean, Dish> mostCaloricPartitionedByVegetarian = menu.stream()
.collect(Collectors.partitioningBy(Dish::getVegetarian,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get)));
System.out.println(mostCaloricPartitionedByVegetarian); // {false=Dish{name='猪肉'}, true=Dish{name='披萨'}}Collectors 类的静态工厂方法
| 工厂方法 | 返回类型 | 用途 | 使用示例 |
|---|---|---|---|
toList | List<T> | 把流中所有项目收集到一个 List | List<Dish> dishes = menuStream.collect(toList()); |
toSet | Set<T> | 把流中所有项目收集到一个 Set,删除重复项 | Set<Dish> dishes = menuStream.collect(toSet()); |
toCollection | Collection<T> | 把流中所有项目收集到给定的供应源创建的集合 | Collection<Dish> dishes = menuStream.collect(toCollection(), ArrayList::new); |
counting | Long | 计算流中元素的个数 | long howManyDishes = menuStream.collect(counting()); |
summingInt | Integer | 对流中项目的一个整数属性求和 | int totalCalories = menuStream.collect(summingInt(Dish::getCalories)); |
averagingInt | Double | 计算流中项目 Integer 属性的平均值 | double avgCalories = menuStream.collect(averagingInt(Dish::getCalories)); |
summarizingInt | IntSummaryStatistics | 收集关于流中项目 Integer 属性的统计值,例如最大、最小、总和与平均值 | IntSummaryStatistics menuStatistics = menuStream.collect(summarizingInt(Dish::getCalories)); |
joining | String | 连接对流中每个项目调用 toString 方法所生成的字符串 | String shortMenu = menuStream.map(Dish::getName).collect(joining(", ")); |
maxBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最大元素的 Optional,或如果流为空则为 Optional.empty() | Optional<Dish> fattest = menuStream.collect(maxBy(comparingInt(Dish::getCalories))); |
minBy | Optional<T> | 一个包裹了流中按照给定比较器选出的最小元素的 Optional,或如果流为空则为 Optional.empty() | Optional<Dish> lightest = menuStream.collect(minBy(comparingInt(Dish::getCalories))); |
reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用 BinaryOperator 与流中的元素逐个结合,从而将流归约为单个值 | int totalCalories = menuStream.collect(reducing(0, Dish::getCalories, Integer::sum)); |
collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数 | int howManyDishes = menuStream.collect(collectingAndThen(toList(), List::size)); |
groupingBy | Map<K, List<T>> | 根据项目的一个属性的值对流中的项目作问组,并将属性值作为结果 Map 的键 | Map<Dish.Type,List<Dish>> dishesByType = menuStream.collect(groupingBy(Dish::getType)); |
partitioningBy | Map<Boolean,List<T>> | 根据对流中每个项目应用谓词的结果来对项目进行分区 | Map<Boolean,List<Dish>> vegetarianDishes = menuStream.collect(partitioningBy(Dish::isVegetarian)); |
Stream 并行流
并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。
假设需要写一个方法,接受数字 n 作为参数,并返回从 1 到给定参数的所有数字的和。一个直接(也许有点土)的方法是生成一个无穷大的数字流,把它限制到给定的数目,然后用对两个数字求和的 BinaryOperator 来归约这个流,如下所示:
java
public static long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1) // 生成自然数无限流
.limit(n) // 限制到前 n 个数
.reduce(0L, Long::sum); // 对所有数字求和来归纳流
}更传统的做法是:
java
public static long iterativeSum(long n) {
long result = 0;
for (long i = 1L; i <= n; i++) {
result += i;
}
return result;
}这似乎是利用并行处理的好机会,特别是 n 很大的时候。
那怎么入手呢?要对结果变量进行同步吗?用多少个线程呢?谁负责生成数呢?谁来做加法呢?
根本用不着担心啦。用并行流的话,这问题就简单多了!
将顺序流转换为并行流
可以把流转换成并行流,从而让前面的函数归约过程(也就是求和)并行运行——对顺序流调用 parallel 方法:
java
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1) // 生成自然数无限流
.limit(n) // 限制到前 n 个数
.parallel() // 将流转换为并行流
.reduce(0L, Long::sum); // 对所有数字求和来归纳流
}在上面的代码中,对流中所有数字求和的归纳过程的执行方式和上面说的差不多。不同之处在于 Stream 在内部分成了几块,因此可以对不同的块独立并行进行归纳操作。最后,同一个归纳操作会将各个子流的部分归纳结果合并起来,得到整个原始流的归纳结果。
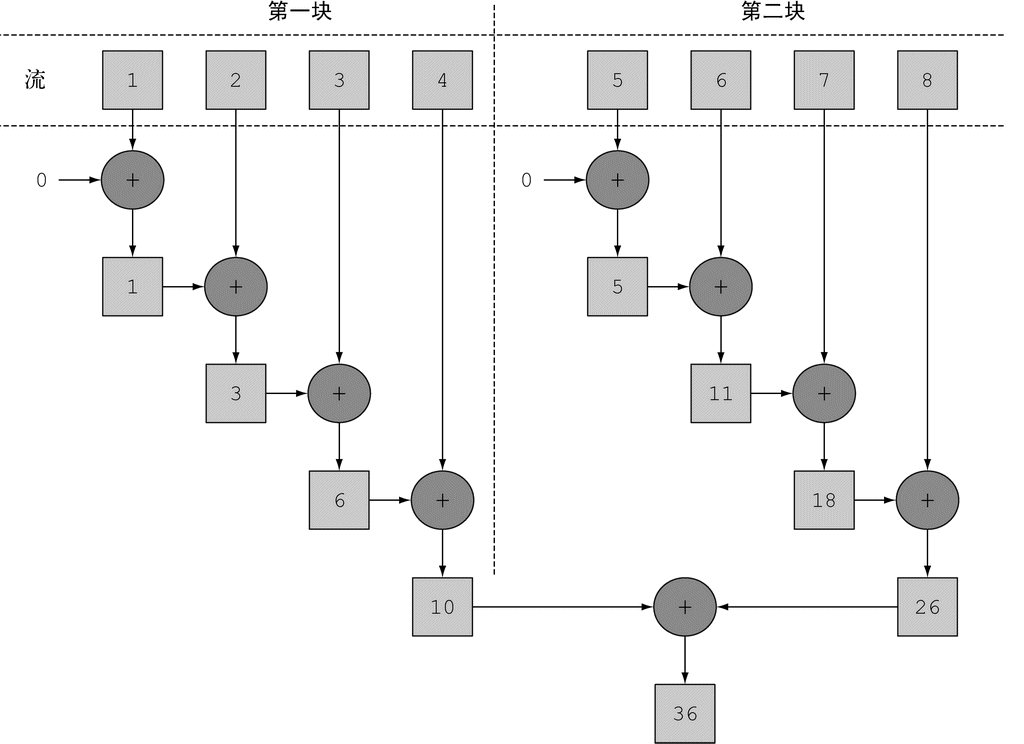
(图片来源:Java 8 实战)
配置并行流使用的线程池
看看流的 parallel 方法,你可能会想,并行流用的线程是从哪儿来的?有多少个?怎么自定义这个过程呢?
并行流内部使用了默认的 ForkJoinPool(分支/合并框架),它默认的线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors() 得到的。
可以通过系统属性 java.util.concurrent.ForkJoinPool.common. parallelism 来改变线程池大小,如下所示:
java
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个并行流指定这个值。一般而言,让 ForkJoinPool 的大小等于处理器数量是个不错的默认值,除非有很好的理由,否则强烈建议不要修改它。
顺序流和并行流的性能对比
都说并行求和方法应该比顺序和迭代方法性能好。然而光靠猜绝对不是什么好办法!特别是在优化性能时,应该始终遵循三个黄金规则:测试,测试,再测试。
测量对前 n 个自然数求和的方法:
java
public static long measureSumPerformance(Function<Long, Long> adder, long n) {
long fastest = Long.MAX_VALUE;
for (int i = 0; i < 10; i++) {
long start = System.nanoTime();
long sum = adder.apply(n);
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("计算结果:" + sum);
if (duration < fastest) {
fastest = duration;
}
}
return fastest;
}这个方法接受一个函数和一个 long 作为参数。它会对传给方法的 long 应用函数 10 次,记录每次执行的时间(以毫秒为单位),并返回最短的一次执行时间。
下面分别使用 sequentialSum、iterativeSum和 parallelSum 方法进行测试对比:
sequentialSum
java// sequentialSum System.out.println("顺序流求和时间为:" + measureSumPerformance(StreamExample::sequentialSum, 10_000_000) + " 毫秒"); // 顺序流求和时间为:85 毫秒iterativeSum
java// iterativeSum System.out.println("传统 for 循环求和时间为:" + measureSumPerformance(StreamExample::iterativeSum, 10_000_000) + " 毫秒"); // 传统 for 循环求和时间为:3 毫秒parallelSum
java// parallelSum System.out.println("并行流求和时间为:" + measureSumPerformance(StreamExample::parallelSum, 10_000_000) + " 毫秒"); // 并行流求和时间为:117 毫秒
太令人失望了吧,求和方法的并行版本比顺序版本要慢很多。
我们先看一下 parallelSum 这个方法的内部细节:
java
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1) // 生成自然数无限流
.limit(n) // 限制到前 n 个数
.parallel() // 将流转换为并行流
.reduce(0L, Long::sum); // 对所有数字求和来归纳流
}这里实际上有两个问题:
iterate生成的是装箱的对象,必须拆箱成基本类型才能求和;很难把
iterate分成多个独立块来并行执行。具体来说,
iterate很难分割成能够独立执行的小块,因为每次应用这个函数都要依赖前一次应用的结果。
使用更有针对性的方法来测试性能
Java 8 API 中有一个叫 LongStream.rangeClosed 的方法。这个方法与 iterate 相比有两个优点:
LongStream.rangeClosed直接产生原始类型的long数字,没有装箱拆箱的开销。LongStream.rangeClosed会生成数字范围,很容易拆分为独立的小块。例如,范围 1~20 可分为 1~5、6~10、11~15 和 16~20。
下面是传统 for 循环求和方法以及重写后的顺序/并行求和的方法:
java
public static long iterativeSum(long n) {
long result = 0;
for (long i = 1L; i <= n; i++) {
result += i;
}
return result;
}
public static long rangedSum(long n) {
return LongStream.rangeClosed(1, n)
.reduce(0L, Long::sum);
}
public static long parallelRangedSum(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.reduce(0L, Long::sum);
}结果为:
java
// iterativeSum
System.out.println("传统 for 循环求和时间为:" +
measureSumPerformance(StreamExample::iterativeSum, 10_000_000) + " 毫秒"); // 传统 for 循环求和时间为:3 毫秒
// rangedSum
System.out.println("顺序流求和时间为:" +
measureSumPerformance(StreamExample::rangedSum, 10_000_000) + " 毫秒"); // 顺序流求和时间为:5 毫秒
// parallelRangedSum
System.out.println("并行流求和时间为:" +
measureSumPerformance(StreamExample::parallelRangedSum, 10_000_000) + " 毫秒"); // 并行流求和时间为:1 毫秒终于,我们得到了一个比顺序执行更快的并行归纳。这也表明,使用正确的数据结构然后使其并行工作能够保证最佳的性能。
总而言之,很多情况下不可能或不方便并行化。然而,在使用并行 Stream 加速代码之前,必须确保用得对;如果结果错了,算得快就毫无意义了。
接口中的默认方法与静态方法
在 Java 8 之前,实现接口的类必须为接口中定义的每个方法提供一个实现,或者从父类中继承它的实现。但是,一旦类库的设计者需要更新接口,向其中加入新的方法,这种方式就会出现问题(现存的实体类往往不在接口设计者的控制范围之内)。
为了解决这一问题,Java 8 中的接口现在支持在声明方法的同时提供实现。通过两种方式可以完成这种操作。其一,Java 8 允许在接口内声明静态方法。其二,Java 8 允许在接口内声明默认方法,通过默认方法可以指定接口方法的默认实现。
我们在前面已经使用了多个默认方法,比如 List 接口中的 sort,以及 Collection 接口中的 stream。
List 接口中的 sort 方法的定义如下:
java
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}请注意返回类型之前的新 default 修饰符。通过它,我们能够知道一个方法是否为默认方法。
由于有了这个新的方法,我们现在可以直接通过调用 sort,对列表中的元素进行排序。
java
List<Integer> numbers = Arrays.asList(3, 5, 1, 2, 6);
numbers.sort(Comparator.naturalOrder()); // sort 是 List 接口的默认方法注意到了吗,我们调用了 Comparator.naturalOrder 方法。这是 Comparator 接口的一个全新的静态方法,它返回一个 Comparator 对象,并按自然序列对其中的元素进行排序(即标准的字母数字方式排序)。
Comparator 接口中的 naturalOrder 方法的定义如下:
java
public static <T extends Comparable<? super T>> Comparator<T> naturalOrder() {
return (Comparator<T>) Comparators.NaturalOrderComparator.INSTANCE;
}Java 8 中的抽象类和抽象接口
抽象类和抽象接口之间的区别是什么呢?它们不都能包含抽象方法和包含方法体的实现吗?
首先,一个类只能继承一个抽象类,但是一个类可以实现多个接口。
其次,一个抽象类可以通过实例变量(字段)保存一个通用状态,而接口是不能有实例变量的。
接口默认方法导致的二义性
我们知道 Java 语言中一个类只能继承一个父类,但是一个类可以实现多个接口。随着默认方法在 Java 8 中引入,有可能出现一个类继承了多个方法而它们使用的却是同样的函数签名。这种情况下,类会选择使用哪一个函数?
java
interface A {
default void hello() {
System.out.println("Hello from A");
}
}
interface B extends A {
default void hello() {
System.out.println("Hello from B");
}
}
class C implements B, A {
public static void main(String... args) {
new C().hello(); // 猜猜打印输出的是什么?
}
}这跟 C++ 语言中著名的菱形继承问题类似,菱形继承问题中一个类同时继承了具有相同函数签名的两个方法。到底该选择哪一个实现呢?
解决二义性的三条规则
在 Java 中,如果一个类使用相同的函数签名从多个地方(比如另一个类或接口)继承了方法,通过三条规则可以进行判断。
类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级。
如果无法依据第一条进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口,即如果 B 继承了 A,那么 B 就比 A 更加具体。
最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。
选择提供了最具体实现的默认方法的接口
在上面的例子中,C 类同时实现了 B 接口和 A 接口,而这两个接口恰巧又都定义了名为 hello 的默认方法。另外,B 又继承自 A。
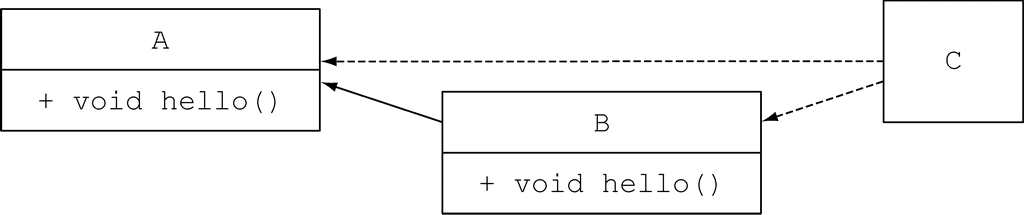
(图片来源:Java 8 实战)
编译器会使用声明的哪一个 hello 方法呢?按照规则 2,应该选择的是提供了最具体实现的默认方法的接口。由于 B 比 A 更具体,所以应该选择 B 的 hello 方法。所以,程序会打印输出“Hello from B”。
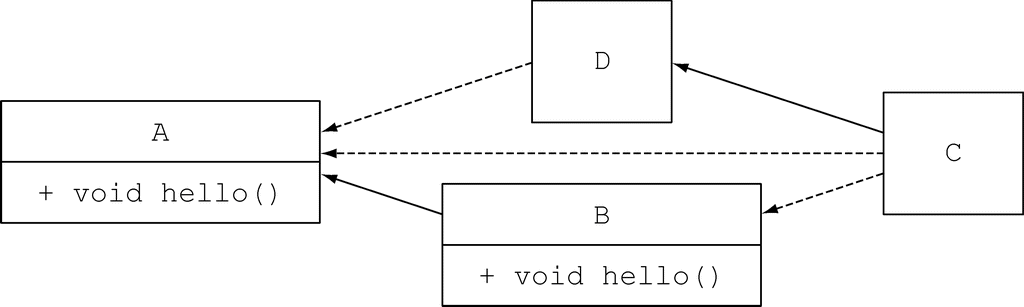
现在,再看看如果 C 像下面这样继承自 D,会发生什么情况:
java
interface A {
default void hello() {
System.out.println("Hello from A");
}
}
interface B extends A {
default void hello() {
System.out.println("Hello from B");
}
}
class D implements A{ }
class C extends D implements B, A {
public static void main(String... args) {
new C().hello();
}
}
(图片来源:Java 8 实战)
依据规则 1,类中声明的方法具有更高的优先级。D 并未覆盖 hello 方法,可是它实现了接口 A,所以它就拥有了接口 A 的默认方法。规则 2 说如果类或者父类没有对应的方法,那么就应该选择提供了最具体实现的接口中的方法。因此,编译器会在接口 A 和接口 B 的 hello 方法之间做选择。由于 B 更加具体,所以程序会再次打印输出“Hello from B”。
冲突及如何显式地消除歧义
到目前为止,这些例子都能够应用前两条判断规则解决。让我们更进一步,假设 B 不再继承 A:
java
interface A {
default void hello() {
System.out.println("Hello from A");
}
}
interface B {
default void hello() {
System.out.println("Hello from B");
}
}
class C implements B, A { }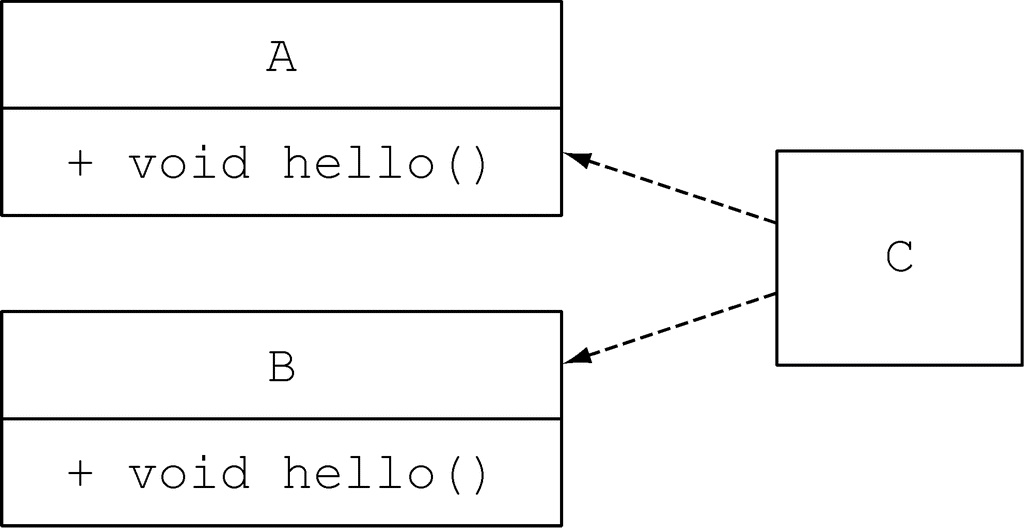
(图片来源:Java 8 实战)
这时规则 2 就无法进行判断了,因为从编译器的角度看没有哪一个接口的实现更加具体,两个都差不多。A 接口和 B 接口的 hello 方法都是有效的选项。所以,Java 编译器这时就会抛出一个编译错误,因为它无法判断哪一个方法更合适:“Error: class C inherits unrelated defaults for hello() from types B and A.”
解决这种两个可能的有效方法之间的冲突,没有太多方案;只能显式地决定希望在 C 中使用哪一个方法。Java 8 中引入了一种新的语法 X.super.m(…),其中 X 是希望调用的 m 方法所在的父接口。
举例来说,如果希望 C 使用来自于 B 的默认方法,它的调用方式看起来就如下所示:
java
class C implements B, A {
public void hello() {
B.super.hello();
}
}菱形问题
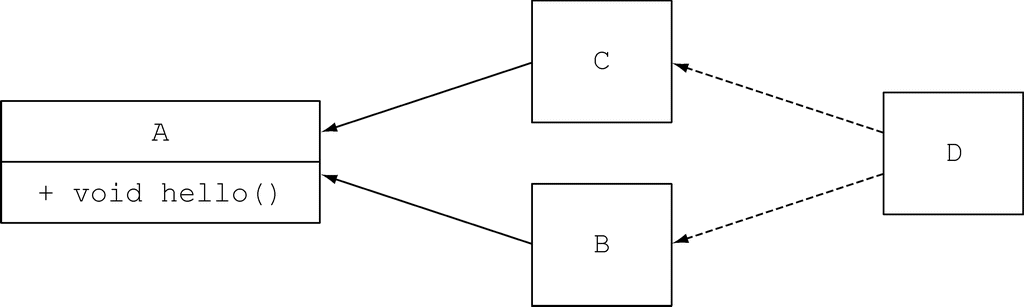
考虑最后一种场景,它亦是 C++ 里中最令人头痛的难题。
java
interface A {
default void hello() {
System.out.println("Hello from A");
}
}
interface B extends A { }
interface C extends A { }
class D implements B, C {
public static void main(String... args) {
new D().hello(); // 猜猜打印输出的是什么?
}
}
(图片来源:Java 8 实战)
这种问题叫“菱形问题”,因为类的继承关系图形状像菱形。
这种情况下类 D 中的默认方法到底继承自什么地方 ——源自 B 的默认方法,还是源自 C 的默认方法?实际上只有一个方法声明可以选择,只有 A 声明了一个默认方法。由于这个接口是 D 的父接口,代码会打印输出“Hello from A”。
用 Optional 取代 null
如果你作为 Java 程序员曾经遭遇过 NullPointerException,请举起手。如果这是你最常遭遇的异常,请继续举手。NullPointerException 让我们无能为力,这是我们为了方便使用了像 null 引用这样的构造所付出的代价。
假设需要处理下面这样的嵌套对象,这是一个拥有汽车及汽车保险的客户。
java
public class Person {
private Car car;
public Car getCar() { return car; }
}
public class Car {
private Insurance insurance;
public Insurance getInsurance() { return insurance; }
}
public class Insurance {
private String name;
public String getName() { return name; }
}那么,下面这段代码存在怎样的问题呢?
java
public String getCarInsuranceName(Person person) {
return person.getCar().getInsurance().getName();
}在实践中,一种比较常见的做法是返回一个 null 引用,表示该值的缺失,即用户没有车。而接下来,对 getInsurance 的调用会返回 null 引用的 insurance,这会导致运行时出现一个 NullPointerException,终止程序的运行。但这还不是全部。如果返回的 person 值为 null 会怎样?如果 getInsurance 的返回值也是 null,结果又会怎样?
采用防御式检查减少 NullPointerException
怎样做才能避免这种不期而至的 NullPointerException呢?通常,可以在需要的地方添加 null 的检查(过于激进的防御式检查甚至会在不太需要的地方添加检测代码),并且添加的方式往往各有不同。
下面这个例子是试图在方法中避免 NullPointerException 的第一次尝试。
null-安全的第一种尝试:深层质疑
javapublic String getCarInsuranceName(Person person) { if (person != null) { Car car = person.getCar(); if (car != null) { Insurance insurance = car.getInsurance(); if (insurance != null) { return insurance.getName(); } } } return "Unknown"; }
标记为“深层质疑”,原因是它不断重复着一种模式:每次你不确定一个变量是否为 null 时,都需要添加一个进一步嵌套的 if 块,也增加了代码缩进的层数。很明显,这种方式不具备扩展性,同时还牺牲了代码的可读性。
null-安全的第二种尝试:过多的退出语句
javapublic String getCarInsuranceName(Person person) { if (person == null) { return "Unknown"; } Car car = person.getCar(); if (car == null) { return "Unknown"; } Insurance insurance = car.getInsurance(); if (insurance == null) { return "Unknown"; } return insurance.getName(); }
第二种尝试中,我们试图避免深层递归的 if 语句块,采用了一种不同的策略:每次遭遇 null 变量,都返回一个字符串常量“Unknown”。然而,这种方案远非理想,现在这个方法有了四个截然不同的退出点,使得代码的维护异常艰难。更糟的是,发生 null 时返回的默认值,即字符串“Unknown”在三个不同的地方重复出现——出现拼写错误的概率不小!当然,你可能会说,我们可以用把它们抽取到一个常量中的方式避免这种问题。
进一步而言,这种流程是极易出错的;如果忘记检查了那个可能为 null 的属性会怎样?
null 带来的种种问题
在 Java 程序开发中使用 null 会带来理论和实际操作上的种种问题。
它是错误之源。
NullPointerException是目前 Java 程序开发中最典型的异常。它会使代码膨胀。
它让代码充斥着深度嵌套的
null检查,代码的可读性糟糕透顶。它自身是毫无意义的。
null自身没有任何的语义,它代表的是在静态类型语言中以一种错误的方式对缺失变量值的建模。它破坏了 Java 的哲学。
Java 一直试图避免让程序员意识到指针的存在,唯一的例外是:
null指针。它在 Java 的类型系统上开了个口子。
null并不属于任何类型,这意味着它可以被赋值给任意引用类型的变量。这会导致问题,原因是当这个变量被传递到系统中的另一个部分后,你将无法获知这个null变量最初的赋值到底是什么类型。
Optional 类
Java 8 中引入了一个新的类 java.util.Optional<T>。这是一个封装 Optional 值的类。
举例来说,使用新的类意味着,如果不确定一个人有没有车,那么 Person 类内部的 car 变量就不应该声明为 Car,而是应该直接将其声明为 Optional<Car> 类型。
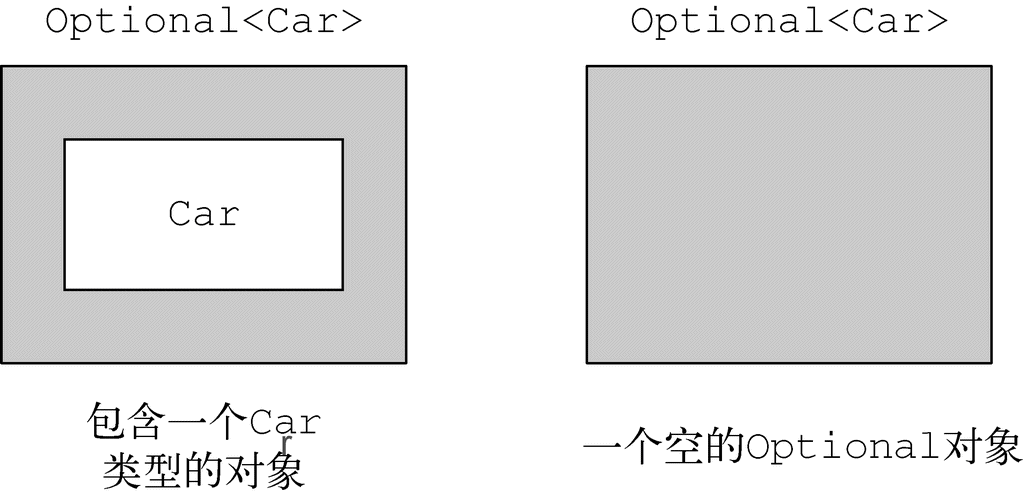
(图片来源:Java 8 实战)
使用 Optional 重新定义 Person/Car/Insurance 的数据模型:
java
public class Person {
private Optional<Car> car; // 人可能有车,也可能没有车,因此将这个字段声明为 Optional
public Optional<Car> getCar() { return car; }
}
public class Car {
private Optional<Insurance> insurance; // 车可能进行了保险,也可能没有保险,所以将这个字段声明为 Optional
public Optional<Insurance> getInsurance() { return insurance; }
}
public class Insurance {
private String name; // 保险公司必须有名字
public String getName() { return name; }
}引入 Optional 类的意图并非要消除每一个 null 引用。与此相反,它的目标是帮助我们更好地设计出普适的 API,让程序员看到方法签名,就能了解它是否接受一个 Optional 的值。
应用Optional
但是,我们该如何使用呢?用这种方式能做什么,或者怎样使用 Optional 封装的值呢?
创建 Optional 对象
使用 Optional 之前,首先需要学习的是如何创建 Optional 对象。完成这一任务有多种方法。
声明一个空的 Optional
通过静态工厂方法
Optional.empty,创建一个空的Optional对象:java// empty Optional<Car> empty = Optional.empty(); Optional<Object> empty1 = Optional.empty(); Optional<String> empty2 = Optional.empty(); Optional<List<Integer>> empty3 = Optional.empty();Optional<T>中的T可以是任意引用类型。依据一个非空值创建 Optional
使用静态工厂方法
Optional.of,依据一个非空值创建一个Optional对象:java// of Optional<Car> carOptional = Optional.of(car); Optional<Object> objectOptional = Optional.of(new Object()); Optional<String> stringOptional = Optional.of("Hello"); Optional<List<Integer>> listOptional = Optional.of(Arrays.asList(1, 2, 3));如果
Optional<T>中的T是空值,会立即抛出一个NullPointerException。javaOptional<Object> nullOptional = Optional.of(null); // NullPointerException可接受 null 的 Optional
使用静态工厂方法
Optional.ofNullable,可以创建一个允许null值的Optional对象:java// ofNullable Optional<Car> carOptional1 = Optional.of(car); Optional<Object> objectOptional1 = Optional.ofNullable(new Object()); Optional<String> stringOptional1 = Optional.ofNullable("Hello"); Optional<List<Integer>> listOptional1 = Optional.ofNullable(Arrays.asList(1, 2, 3)); Optional<Object> nullOptional1 = Optional.ofNullable(null);
如何获取 Optional 变量中的值呢?
Optional 提供了一个 get 方法,它能非常精准地完成这项工作。不过 get 方法在遭遇到空的 Optional 对象时也会抛出异常。
java
// get
Optional<Car> carOptional = Optional.of(car);
carOptional.get(); // car
car = null;
Optional<Car> carOptional1 = Optional.of(car);
Optional.of(car).get(); // NullPointerException难道还是无法摆脱由 null 引起的代码维护的梦魇?
我们首先从无需显式检查的 Optional 值的使用入手,这些方法与 Stream 中的某些操作极其相似。
使用 map 从 Optional 对象中提取和转换值
从对象中提取信息是一种比较常见的模式。
比如,想要从 insurance 公司对象中提取公司的名称。提取名称之前,需要检查 insurance 对象是否为 null:
java
String name = null;
if (insurance != null) {
name = insurance.getName();
}为了支持这种模式,Optional 提供了一个 map 方法。它的工作方式如下:
java
Optional<Insurance> optInsurance = Optional.ofNullable(insurance);
Optional<String> name = optInsurance.map(Insurance::getName);map 操作会将提供的函数应用于流的每个元素。我们可以把 Optional 对象看成一种特殊的集合数据,它至多包含一个元素。如果 Optional 包含一个值,那函数就将该值作为参数传递给 map,对该值进行转换。如果 Optional 为空,就什么也不做。
前文的代码里用安全的方式链接了多个方法:
java
public String getCarInsuranceName(Person person) {
return person.getCar().getInsurance().getName();
}现在我们可以用 map 重构上面的代码:
java
public String getCarInsuranceName(Person person) {
Optional<Person> optPerson = Optional.of(person);
return optPerson.map(Person::getCar)
.map(Car::getInsurance)
.map(Insurance::getName);
}不幸的是,这段代码无法通过编译:
java
Error:(100, 30) java: 不兼容的类型: 方法引用无效
无法将 类 Car中的 方法 getInsurance应用到给定类型
需要: 没有参数
找到: java.util.Optional<Car>
原因: 实际参数列表和形式参数列表长度不同为什么呢?optPerson 是 Optional<Person> 类型的变量, 调用 map 方法应该没有问题。但 getCar 返回的是一个 Optional<Car> 类型的对象,这意味着 map 操作的结果是一个 Optional<Optional<Car>> 类型的对象。因此,它对 getInsurance 的调用是非法的,因为最外层的 optional 对象包含了另一个 optional 对象的值,而它当然不会支持 getInsurance 方法。
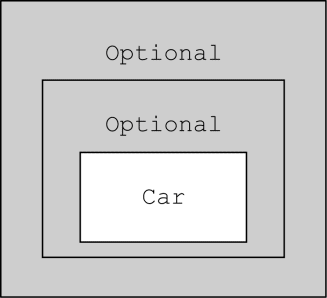
(图片来源:Java 8 实战)
所以,我们该如何解决这个问题呢?
使用 flatMap 链接 Optional 对象
让我们再回顾一下在流上使用过 flatMap 方法。使用流时,flatMap 方法接受一个函数作为参数,这个函数的返回值是另一个流。这个方法会应用到流中的每一个元素,最终形成一个新的流的流。但是 flagMap 会用流的内容替换每个新生成的流。换句话说,由方法生成的各个流会被合并或者扁平化为一个单一的流。这里我们希望的结果其实也是类似的-想要的是将两层的 optional 合并为一个。
java
// flatMap
public String getCarInsuranceName(Person person) {
Optional<Person> optPerson = Optional.of(person);
return optPerson.flatMap(Person::getCar)
.flatMap(Car::getInsurance)
.map(Insurance::getName)
.orElse("Unknown"); // 如果 Optional 的结果值为空,设置默认值
}默认行为及解引用 Optional 对象
Optional 类提供了多种方法读取 Optional 实例中的变量值。
get()是这些方法中最简单但又最不安全的方法。如果变量存在,它直接返回封装的变量值,否则就抛出一个NoSuchElementException异常。所以,除非可以非常确定Optional变量一定包含值,否则使用这个方法是个相当糟糕的主意。orElse(T other)允许在Optional对象不包含值时提供一个默认值,就像上面使用的那样。orElseGet(Supplier<? extends T> other)是orElse方法的延迟调用版,Supplier方法只有在Optional对象不含值时才执行调用。如果创建默认值是件耗时费力的工作,应该考虑采用这种方式(借此提升程序的性能),或者需要非常确定某个方法仅在Optional为空时才进行调用,也可以考虑该方式(这种情况有严格的限制条件)。orElseThrow(Supplier<? extends X> exceptionSupplier)和get方法非常类似,它们遭遇Optional对象为空时都会抛出一个异常,但是使用orElseThrow你可以定制希望抛出的异常类型。ifPresent(Consumer<? super T>)能在变量值存在时执行一个作为参数传入的方法,否则就不进行任何操作。
使用 filter 剔除特定的值
我们经常需要调用某个对象的方法,查看它的某些属性。
比如,需要检查保险公司的名称是否为“平安保险”。为了以一种安全的方式进行这些操作,首先需要确定引用指向的 Insurance 对象是否为 null,之后再调用它的 getName 方法:
java
if (insurance != null && "平安保险".equals(insurance.getName())) {
System.out.println("ok");
}使用 Optional 对象的 filter 方法,这段代码可以重构如下:
java
// filter
Optional<Insurance> optInsurance = Optional.ofNullable(insurance);
optInsurance.filter(insurance1 -> "平安保险".equals(insurance.getName()))
.ifPresent(x -> System.out.println("ok"));filter 方法接受一个谓词作为参数。如果 Optional 对象的值存在,并且它符合谓词的条件,filter 方法就返回其值;否则它就返回一个空的 Optional 对象。
Optional 类的方法
| 方法 | 描述 |
|---|---|
empty | 返回一个空的 Optional 实例 |
filter | 如果值存在并且满足提供的谓词,就返回包含该值的 Optional 对象;否则返回一个空的 Optional 对象 |
flatMap | 如果值存在,就对该值执行提供的 mapping 函数调用,返回一个 Optional 类型的值,否则就返回一个空的 Optional 对象 |
get | 如果该值存在,将该值用 Optional 封装返回,否则抛出一个 NoSuchElementException 异常 |
ifPresent | 如果值存在,就执行使用该值的方法调用,否则什么也不做 |
isPresent | 如果值存在就返回 true,否则返回 false |
map | 如果值存在,就对该值执行提供的 mapping 函数调用 |
of | 将指定值用 Optional 封装之后返回,如果该值为 null,则抛出一个 NullPointerException 异常 |
ofNullable | 将指定值用 Optional 封装之后返回,如果该值为 null,则返回一个空的 Optional 对象 |
orElse | 如果有值则将其返回,否则返回一个默认值 |
orElseGet | 如果有值则将其返回,否则返回一个由指定的 Supplier 接口生成的值 |
orElseThrow | 如果有值则将其返回,否则抛出一个由指定的 Supplier 接口生成的异常 |
新的日期和时间 API
Java 的 API 提供了很多有用的组件,能帮助我们构建复杂的应用。不过,Java API 也不总是完美的。相信大多数有经验的程序员都会赞同 Java 8 之前的库对日期和时间的支持就非常不理想。然而,现在不用太担心了:Java 8 中引入全新的日期和时间 API 就是要解决这一问题。
java.time 包中提供了很多新的类可以帮我们解决问题,它们是 LocalDate、LocalTime、LocalDateTime、Instant、Duration 和 Period。
LocalDate、LocalTime、LocalDateTime、Instant、Duration 以及 Period
LocalDate
开始使用新的日期和时间 API 时,最先碰到的可能是 LocalDate 类。该类的实例是一个不可变对象,它只提供了简单的日期,并不含当天的时间信息。另外,它也不附带任何与时区相关的信息。
可以通过静态工厂方法 of 创建一个 LocalDate 实例。LocalDate 实例提供了多种方法来读取常用的值,比如年份、月份、星期几等。
创建一个 LocalDate 对象并读取其值:
java
LocalDate nowDate = LocalDate.now(); // 当前日期
LocalDate localDate = LocalDate.of(2020, 5, 20); // 2020-05-20
int year = localDate.getYear(); // 2020
int monthValue = localDate.getMonthValue(); // 5
Month month = localDate.getMonth(); // MAY(月份的枚举类型)
int day = localDate.getDayOfMonth(); // 20
DayOfWeek dayOfWeek = localDate.getDayOfWeek(); // WEDNESDAY(星期的枚举类型)
int lengthOfMonth = localDate.lengthOfMonth();// 31 (五月份的天数)
boolean leapYear = localDate.isLeapYear(); // true (是闰年)还可以通过传递一个 TemporalField 参数给 get 方法拿到同样的信息。TemporalField 是一个接口,它定义了如何访问 temporal 对象某个字段的值。
ChronoField 枚举实现了这一接口,所以可以很方便地使用 get 方法得到枚举元素的值:
java
int year = localDate.get(ChronoField.YEAR); // 2020
int monthValue = localDate.get(ChronoField.MONTH_OF_YEAR); // 5
int day = localDate.get(ChronoField.DAY_OF_MONTH); // 20
int dayOfWeek = localDate.get(ChronoField.DAY_OF_WEEK); // 3LocalTime
类似地,一天中的时间,比如 09:45:20,可以使用 LocalTime 类表示。可以使用 of 重载的两个工厂方法创建 LocalTime 的实例。第一个重载函数接收小时和分钟,第二个重载函数同时还接收秒。
同 LocalDate 一样,LocalTime 类也提供了一些 get 方法访问这些变量的值。
创建 LocalTime 并读取其值:
java
LocalTime nowTime = LocalTime.now(); // 当前时间
LocalTime localTime = LocalTime.of(9, 45, 20); // 09:45:20
int hour = localTime.getHour(); // 9
int minute = localTime.getMinute(); // 45
int second = localTime.getSecond(); // 20通过 ChronoField 枚举读取其值:
java
int hour = localTime.get(ChronoField.HOUR_OF_DAY); // 9
int minute = localTime.get(ChronoField.MINUTE_OF_HOUR); // 45
int second = localTime.get(ChronoField.SECOND_OF_MINUTE); // 20LocalDateTime
LocalDateTime 是 LocalDate 和 LocalTime 的合体。它同时表示了日期和时间,但不带有时区信息。可以直接创建,也可以通过合并日期和时间对象构造。
直接创建 LocalDateTime 对象,或者通过合并日期和时间的方式创建:
java
LocalDateTime nowDateTime = LocalDateTime.now(); // 当前日期时间
LocalDateTime localDateTime = LocalDateTime.of(2020, 5, 20, 9, 45, 20); // 2020-05-20T09:45:20
LocalDateTime localDateTime1 = LocalDateTime.of(LocalDate.now(), LocalTime.now());
LocalDateTime localDateTime2 = LocalDate.of(2020, 5, 20).atTime(9, 45, 20); // 2020-05-20T09:45:20
LocalDateTime localDateTime3 = LocalTime.of(9, 45, 20).atDate(LocalDate.of(2020, 5, 20)); // 2020-05-20T09:45:20可以使用 toLocalDate 或者 toLocalTime 方法,从 LocalDateTime 中提取 LocalDate 或者 LocalTime 组件:
java
LocalDate localDate = localDateTime.toLocalDate(); // 2020-05-20
LocalTime localTime = localDateTime.toLocalTime(); // 09:45:20提示
LocalDate、LocalTime 和 LocalDateTime 都可以通过解析代表它们的字符串创建。使用静态方法 parse,可以实现这一目的:
java
LocalDate date = LocalDate.parse("2020-05-20");
LocalTime time = LocalTime.parse("09:45:20");
LocalDateTime dateTime = LocalDateTime.parse("2020-05-20 09:45:20");Instant
作为人,我们习惯于以星期几、几号、几点、几分这样的方式理解日期和时间。毫无疑问,这种方式对于计算机而言并不容易理解。从计算机的角度来看,建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数。这也是新的 java.time.Instant 类对时间建模的方式,基本上它是以 Unix 元年时间(传统的设定为 UTC 时区 1970 年 1 月 1 日午夜时分)开始所经历的秒数进行计算。
可以通过向静态工厂方法 ofEpochSecond 传递一个代表秒数的值创建一个该类的实例。静态工厂方法 ofEpochSecond 还有一个增强的重载版本,它接收第二个以纳秒为单位的参数值,对传入作为秒数的参数进行调整。重载的版本会调整纳秒参数,确保保存的纳秒分片在 0 到 999 999 999 之间。这意味着下面这些对 ofEpochSecond 工厂方法的调用会返回几乎同样的 Instant 对象:
java
Instant instant = Instant.ofEpochSecond(3);
Instant.ofEpochSecond(3, 0);
Instant.ofEpochSecond(2, 1_000_000_000); // 2 秒之后再加上 100 万纳秒(1 秒)
Instant.ofEpochSecond(4, -1_000_000_000); // 4 秒之前的 100 万纳秒(1 秒)注意
Instant 类也支持静态工厂方法 now,它能够获取当前时刻的时间戳。特别强调一点,Instant 的设计初衷是为了便于机器使用。它包含的是由秒及纳秒所构成的数字。所以,它无法处理那些我们非常容易理解的时间单位。比如下面这段语句:
java
int day = Instant.now().get(ChronoField.DAY_OF_MONTH);它会抛出下面这样的异常:
java
java.time.temporal.UnsupportedTemporalTypeException: Unsupported field: DayOfMonth但是可以通过 Duration 和 Period 类使用 Instant。
定义 Duration 或 Period
目前为止,我们看到的所有类都实现了 Temporal 接口,Temporal 接口定义了如何读取和操纵为时间建模的对象的值。很自然地会想到,我们需要创建两个 Temporal 对象之间的 duration。Duration 类的静态工厂方法 between 就是为这个目的而设计的。
创建两个 LocalTime 对象、两个 LocalDateTime 对象,或者两个 Instant 对象之间的 duration:
java
Duration duration = Duration.between(LocalTime.now(), LocalTime.of(9, 45, 20));
Duration duration1 = Duration.between(LocalDateTime.now(), LocalDateTime.of(2020, 5, 20, 9, 45, 20));
Duration duration2 = Duration.between(Instant.now(), Instant.ofEpochSecond(3));由于 Duration 类主要用于以秒和纳秒衡量时间的长短,不能仅向 between 方法传递一个 LocalDate 对象做参数:
java
Duration.between(LocalDate.now(), LocalDate.of(2020, 5, 20));它会抛出下面这样的异常:
java
java.time.temporal.UnsupportedTemporalTypeException: Unsupported unit: Seconds如果需要以年、月或者日的方式对多个时间单位建模,可以使用 Period 类。
使用该类的工厂方法 between,可以得到两个 LocalDate 之间的时长:
java
Period period = Period.between(LocalDate.of(2020, 5, 20),
LocalDate.of(2020, 5, 28));最后,Duration 和 Period 类都提供了很多非常方便的工厂类,直接创建对应的实例;换句话说,就像下面这段代码那样,不再是只能以两个 temporal 对象的差值的方式来定义它们的对象。
java
Duration threeMinutes = Duration.ofMinutes(3);
Duration threeMinutes1 = Duration.of(3, ChronoUnit.MINUTES);
Period tenDays = Period.ofDays(10);
Period threeWeeks = Period.ofWeeks(3);
Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1);Duration 类和 Period 类中表示时间间隔的通用方法:
| 方法名 | 是否是静态方法 | 方法描述 |
|---|---|---|
between | 是 | 创建两个时间点之间的 interval |
from | 是 | 由一个临时时间点创建 interval |
of | 是 | 由它的组成部分创建 interval 的实例 |
parse | 是 | 由字符串创建 interval 的实例 |
addTo | 否 | 创建该 interval 的副本,并将其叠加到某个指定的 Temporal 对象 |
get | 否 | 读取该 interval 的状态 |
isNegative | 否 | 检查该 interval 是否为负值,不包含零 |
isZero | 否 | 检查该 interval 的时长是否为零 |
minus | 否 | 通过减去一定的时间创建该 interval 的副本 |
multipliedBy | 否 | 将 interval 的值乘以某个标量创建该 interval 的副本 |
negated | 否 | 以忽略某个时长的方式创建该 interval 的副本 |
plus | 否 | 以增加某个指定的时长的方式创建该 interval 的副本 |
subtractFrom | 否 | 从指定的 Temporal 对象中减去该 interval |
操纵、解析和格式化日期
如果已经有一个 LocalDate 对象,想要创建它的一个修改版,最直接也最简单的方法是使用 withAttribute 方法。withAttribute 方法会创建对象的一个副本,并按照需要修改它的属性。注意,下面的这段代码中所有的方法都返回一个修改了属性的对象。它们都不会修改原来的对象!
以比较直观的方式操纵 LocalDate 的属性:
java
LocalDate localDate = LocalDate.of(2020, 5, 20); // 2020-05-20
LocalDate localDate1 = localDate.withYear(2019); // 2019-05-20
LocalDate localDate2 = localDate1.withDayOfMonth(28); // 2019-05-28
LocalDate localDate3 = localDate2.with(ChronoField.MONTH_OF_YEAR, 10); // 2019-10-28甚至还能以声明的方式操纵 LocalDate 对象。比如,可以像下面这段代码那样加上或者减去一段时间。
以相对方式修改 LocalDate 对象的属性:
java
LocalDate localDate = LocalDate.of(2020, 5, 20); // 2020-05-20
LocalDate localDate1 = localDate.plusWeeks(1); // 2020-05-27
LocalDate localDate2 = localDate1.minusYears(3); // 2017-05-27
LocalDate localDate3 = localDate2.plus(6, ChronoUnit.MONTHS); // 2017-11-27LocalDate、LocalTime、LocalDateTime 以及 Instant 表示时间点的日期-时间类的通用方法:
| 方法名 | 是否是静态方法 | 方法描述 |
|---|---|---|
from | 是 | 依据传入的 Temporal 对象创建对象实例 |
now | 是 | 依据系统时钟创建 Temporal 对象 |
of | 是 | 由 Temporal 对象的某个部分创建该对象的实例 |
parse | 是 | 由字符串创建 Temporal 对象的实例 |
atOffset | 否 | 将 Temporal 对象和某个时区偏移相结合 |
atZone | 否 | 将 Temporal 对象和某个时区相结合 |
format | 否 | 使用某个指定的格式器将 Temporal 对象转换为字符串(Instant 类不提供该方法) |
get | 否 | 读取 Temporal 对象的某一部分的值 |
minus | 否 | 创建 Temporal 对象的一个副本,通过将当前 Temporal 对象的值减去一定的时长创建该副本 |
plus | 否 | 创建 Temporal 对象的一个副本,通过将当前 Temporal 对象的值加上一定的时长创建该副本 |
with | 否 | 以该 Temporal 对象为模板,对某些状态进行修改创建该对象的副本 |
使用 TemporalAdjuster
截至目前,我们所看到的所有日期操作都是相对比较直接的。有的时候,需要进行一些更加复杂的操作,比如,将日期调整到下个周日、下个工作日,或者是本月的最后一天。这时,可以使用重载版本的 with 方法,向其传递一个提供了更多定制化选择的 TemporalAdjuster 对象,更加灵活地处理日期。
使用预定义的 TemporalAdjuster
对于最常见的用例,日期和时间API已经提供了大量预定义的 TemporalAdjuster,可以通过 TemporalAdjusters 类的静态工厂方法访问它们。
java
LocalDate localDate = LocalDate.of(2020, 5, 20); // 2020-05-20
LocalDate localDate1 = localDate.with(TemporalAdjusters.nextOrSame(DayOfWeek.SUNDAY)); // 2020-05-24
LocalDate localDate2 = localDate.with(TemporalAdjusters.lastDayOfMonth()); // 2020-05-31TemporalAdjusters 类中的工厂方法:
| 方法名 | 描述 |
|---|---|
dayOfWeekInMonth | 创建一个新的日期,它的值为同一个月中每一周的第几天 |
firstDayOfMonth | 创建一个新的日期,它的值为当月的第一天 |
firstDayOfNextMonth | 创建一个新的日期,它的值为下月的第一天 |
firstDayOfNextYear | 创建一个新的日期,它的值为明年的第一天 |
firstDayOfYear | 创建一个新的日期,它的值为当年的第一天 |
firstInMonth | 创建一个新的日期,它的值为同一个月中,第一个符合星期几要求的值 |
lastDayOfMonth | 创建一个新的日期,它的值为当月的最后一天 |
lastDayOfNextMonth | 创建一个新的日期,它的值为下月的最后一天 |
lastDayOfNextYear | 创建一个新的日期,它的值为明年的最后一天 |
lastDayOfYear | 创建一个新的日期,它的值为今年的最后一天 |
lastInMonth | 创建一个新的日期,它的值为同一个月中,最后一个符合星期几要求的值 |
next/previous | 创建一个新的日期,并将其值设定为日期调整后或者调整前,第一个符合指定星期几要求的日期 |
nextOrSame/previousOrSame | 创建一个新的日期,并将其值设定为日期调整后或者调整前,第一个符合指定星期几要求的日期,如果该日期已经符合要求,直接返回该对象 |
即使没有找到符合要求的预定义的 TemporalAdjuster,创建自己的 TemporalAdjuster 也并非难事。实际上,TemporalAdjuster 接口只声明了单一的一个方法(这使得它成为了一个函数式接口)。
java
@FunctionalInterface
public interface TemporalAdjuster {
Temporal adjustInto(Temporal temporal);
}这意味着 TemporalAdjuster 接口的实现需要定义如何将一个 Temporal 对象转换为另一个 Temporal 对象。
实现一个定制的 TemporalAdjuster
假如需要设计一个 NextWorkingDay 类,该类实现了 TemporalAdjuster 接口,能够计算明天的日期,同时过滤掉周六和周日这些节假日。
如果当天的星期介于周一至周五之间,日期向后移动一天;如果当天是周六或者周日,则返回下一个周一。
NextWorkingDay 类的实现:
java
public class NextWorkingDay implements TemporalAdjuster {
@Override
public Temporal adjustInto(Temporal temporal) {
DayOfWeek dow =
DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK)); // 读取当前日期
int dayToAdd = 1; // 正常情况,增加 1 天
if (dow == DayOfWeek.FRIDAY) {
dayToAdd = 3; // 如果当天是周五,增加 3 天
} else if (dow == DayOfWeek.SATURDAY) {
dayToAdd = 2; // 如果当天是周六,增加 2 天
}
return temporal.plus(dayToAdd, ChronoUnit.DAYS); // 增加恰当的天数后,返回修改的日期
}
}测试结果如下:
java
LocalDate localDate = LocalDate.of(2020, 5, 22); // 2020-05-22 星期五
LocalDate localDate1 = localDate.with(new NextWorkingDay()); // 2020-05-25 星期一
LocalDate localDate2 = localDate1.with(new NextWorkingDay()); // 2020-05-26 星期二由于 TemporalAdjuster 是一个函数式接口,还能以 Lambda 表达式的方式向该接口传递行为:
java
LocalDate localDate3 = localDate2.with(temporal -> {
DayOfWeek dow =
DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK)); // 读取当前日期
int dayToAdd = 1; // 正常情况,增加 1 天
if (dow == DayOfWeek.FRIDAY) {
dayToAdd = 3; // 如果当天是周五,增加 3 天
} else if (dow == DayOfWeek.SATURDAY) {
dayToAdd = 2; // 如果当天是周六,增加 2 天
}
return temporal.plus(dayToAdd, ChronoUnit.DAYS); // 增加恰当的天数后,返回修改的日期
}); // 2020-05-27 星期三如果想要使用 Lambda 表达式定义 TemporalAdjuster 对象,推荐使用 TemporalAdjusters 类的静态工厂方法 ofDateAdjuster,它接受一个 UnaryOperator<LocalDate> 类型的参数,代码如下:
java
TemporalAdjuster nextWorkingDay = TemporalAdjusters.ofDateAdjuster( temporal -> {
DayOfWeek dow =
DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK)); // 读取当前日期
int dayToAdd = 1; // 正常情况,增加 1 天
if (dow == DayOfWeek.FRIDAY) {
dayToAdd = 3; // 如果当天是周五,增加 3 天
} else if (dow == DayOfWeek.SATURDAY) {
dayToAdd = 2; // 如果当天是周六,增加 2 天
}
return temporal.plus(dayToAdd, ChronoUnit.DAYS); // 增加恰当的天数后,返回修改的日期
});打印输出及解析日期-时间对象
处理日期和时间对象时,格式化以及解析日期-时间对象是另一个非常重要的功能。新的 java.time.format 包就是特别为这个目的而设计的。这个包中,最重要的类是 DateTimeFormatter。创建格式器最简单的方法是通过它的静态工厂方法以及常量。像 BASIC_ISO_DATE 和 ISO_LOCAL_DATE 这样的常量是 DateTimeFormatter 类的预定义实例。所有的 DateTimeFormatter 实例都能用于以一定的格式创建代表特定日期或时间的字符串。
比如,下面的这个例子中,使用了两个不同的格式器生成了字符串:
java
LocalDate localDate = LocalDate.of(2020, 5, 20);
String s = localDate.format(DateTimeFormatter.BASIC_ISO_DATE); // 20200520
String s1 = localDate.format(DateTimeFormatter.ISO_LOCAL_DATE); // 2020-05-20也可以通过解析代表日期或时间的字符串重新创建该日期对象。所有的日期和时间 API 都提供了表示时间点或者时间段的工厂方法,可以使用工厂方法 parse 达到重创该日期对象的目的:
java
LocalDate localDate = LocalDate.parse("20200520", DateTimeFormatter.BASIC_ISO_DATE);
LocalDate localDate1 = LocalDate.parse("2020-05-20", DateTimeFormatter.ISO_LOCAL_DATE);和老的 java.util.DateFormat 相比较,所有的 DateTimeFormatter 实例都是线程安全的。所以能够以单例模式创建格式器实例,就像 DateTimeFormatter 所定义的那些常量,并能在多个线程间共享这些实例。
DateTimeFormatter 类还支持一个 ofPattern 静态工厂方法,它可以按照某个特定的模式创建格式器:
java
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate localDate = LocalDate.of(2020, 5, 20);
String s = localDate.format(dateTimeFormatter); // 2020-05-20
LocalDate localDate1 = LocalDate.parse(s, dateTimeFormatter);ofPattern 方法也提供了一个重载的版本,使用它可以创建某个 Locale 的格式器:
java
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd E", Locale.CHINESE);
LocalDate localDate = LocalDate.of(2020, 5, 20);
String s = localDate.format(dateTimeFormatter); // 2020-05-20 周三
LocalDate localDate1 = LocalDate.parse(s, dateTimeFormatter);如果还需要更加细粒度的控制,DateTimeFormatterBuilder 类提供了更复杂的格式器,可以选择恰当的方法,一步一步地构造自己的格式器。它还提供了非常强大的解析功能,比如区分大小写的解析、柔性解析(允许解析器使用启发式的机制去解析输入,不精确地匹配指定的模式)、填充。
比如,通过 DateTimeFormatterBuilder 来实现我们在上面使用的 dateTimeFormatter:
java
DateTimeFormatter dateTimeFormatter = new DateTimeFormatterBuilder()
.appendValue(ChronoField.YEAR, 4)
.appendLiteral('-')
.appendValue(ChronoField.MONTH_OF_YEAR, 2)
.appendLiteral('-')
.appendValue(ChronoField.DAY_OF_MONTH, 2)
.appendLiteral(' ')
.appendText(ChronoField.DAY_OF_WEEK, TextStyle.SHORT)
.toFormatter(Locale.CHINESE);
LocalDate localDate = LocalDate.of(2020, 5, 20);
String s = localDate.format(dateTimeFormatter); // 2020-05-20 周三
LocalDate localDate1 = LocalDate.parse(s, dateTimeFormatter);处理不同的时区和历法
之前我们看到的日期和时间的种类都不包含时区信息。时区的处理是新版日期和时间 API 新增加的重要功能,使用新版日期和时间 API 时区的处理被极大地简化了。
新的 java.time.ZoneId 类是老版 java.util.TimeZone 的替代品。它的设计目标就是要让我们无需为时区处理的复杂和繁琐而操心,比如处理夏令时(Daylight Saving Time,DST)这种问题。跟其他日期和时间类一样,ZoneId 类也是无法修改的。
时区是按照一定的规则将区域划分成的标准时间相同的区间。可以通过调用 ZoneId 的 getAvailableZoneIds() 得到全部的时区 ID。
java
Set<String> availableZoneIds = ZoneId.getAvailableZoneIds();每个特定的 ZoneId 对象都由一个地区 ID 标识:
java
ZoneId zoneId = ZoneId.of("Asia/Shanghai");地区 ID 都为“{区域}/{城市}”的格式,这些地区集合的设定都由互联网数字分配机构(Internet Assigned Numbers Authority,IANA)的时区数据库提供。
可以通过 ZoneId.systemDefault() 静态方法得到当前时区的 ZoneId 对象:
java
ZoneId zoneId = ZoneId.systemDefault();一旦得到一个 ZoneId 对象,就可以将它与 LocalDate、LocalDateTime 或者是 Instant 对象整合起来,构造为一个 ZonedDateTime 实例,它代表了相对于指定时区的时间点。
为时间点添加时区信息:
java
LocalDate localDate = LocalDate.of(2020, 5, 20);
ZonedDateTime zonedDateTime = localDate.atStartOfDay(zoneId);
LocalDateTime localDateTime = LocalDateTime.of(2020, 5, 20, 9, 45, 20);
ZonedDateTime zonedDateTime1 = localDateTime.atZone(zoneId);
Instant instant = Instant.now();
ZonedDateTime zonedDateTime2 = instant.atZone(zoneId);LocaleDate、LocalTime、LocalDateTime 以及 ZoneId 之间的差异:
(图片来源:Java 8 实战)
通过 ZoneId,还可以将 LocalDateTime 转换为 Instant:
java
LocalDateTime localDateTime = LocalDateTime.of(2020, 5, 20, 9, 45, 20);
Instant instant = localDateTime.atZone(zoneId).toInstant();也可以通过反向的方式得到 LocalDateTime 对象:
java
Instant instant = Instant.now();
LocalDateTime localDateTime = instant.atZone(zoneId).toLocalDateTime();
LocalDateTime localDateTime1 = LocalDateTime.ofInstant(instant, zoneId);